编者按:2023 年 8月14日,第七届GAIR全球人工智能与机器人大会在新加坡乌节大酒店正式开幕。论坛由GAIR研究院、小编、世界科技出版社、科特勒咨询集团联合主办。
大会共开设10个主题论坛,聚焦大模型时代下的AIGC、Infra、生命科学、教育,SaaS、web3、跨境电商等领域的变革创新。此次大会是在大模型技术爆炸时代,首个出海的AI顶级论坛,也是中国人工智能影响力的一次跨境溢出。
在第一天的“青年科学论坛家”专场上,南洋理工大学副教授张含望带来了以《视觉识别中的因果关系》为主题的演讲。
张含望认为,对于当前的大模型来说,如果想要真正突破一些最底层逻辑上的问题,因果关系(Causality)是一条必经之路。
在他看来,在多模态模型或大语言模型的研究中,偏见(bias)是常见问题。随着模型规模的不断扩大,它可能会越来越智能,但偏见问题依旧存在。
这就意味着,如果不把因果关系加上去,大模型只是在进行强行关联,幸运的话,模型在回答问题时能够给出正确答案,否则就会“胡说八道”。这是因为它背后的关联是错误的,把共生关系当成了因果关系。
“共生不等于因果,经常发生的事情不一定是因果关系。”
对此,他给出的建议是,大家在做多模态模型的过程中,一方面一定要多关注“等变性”,因为“可拆解性”可以通过数据量堆叠,“等变性”不可以,所以在预训练时要多加注意。
另一方面,目前多模态之间互通的瓶颈在于非语言模态(例如图像)的spatial tokens和语言分布差得太远。
他认为,语言的本质是可递归的符号系统,这也是大语言模型可以推理的基础。
所以,如果想得到真正的多模态大模型,就必须找到一种“可递归,可拆解的”的tokenization的方法,把非语言模态转成“可递归分布”的token。
以下为张含望教授的现场演讲内容,小编作了不改变原意的编辑及整理:
张含望:前面的嘉宾都在讲大语言模型(large language model),那我换一下口味,讲一讲计算机视觉中的因果关系(Causality)。
很不幸的是,从去年年底到今年年初,在大模型风靡的时候,因果关系好像又落入了一种近乎“销声匿迹”的状态。大家的目光和兴奋点几乎都落在大模型的能力表现上面,而因果关系,这一稍微被我们推到一定知名度的领域,又迅速暗淡下去。
在我看来,对于当前的大模型来说,如果想要真正突破一些最底层逻辑上的问题,因果关系(Causality)是一条必经之路。它可能不是一个完整解法,但最起码是一块敲门砖。
01为什么需要因果关系(Causality)?
三四年前,我们就非常在意计算机视觉问题中的偏见(bias),而到了做多模态模型或大语言模型的时候,这些bias依然存在。
也就是说,随着模型规模不断变大,它可能会更加懂事、智能,但在bias上面,还没有一个底层算法能够解决该问题。
这个bias是什么呢?如果你让大模型做一些视觉方面的QA,模型回答的答案是正确的,但是它所看的地方是错的。用现在流行的话来讲,它的中间链条可能是不对的。
就像下面这幅图上面显示的,问题是:女孩吃热狗的时候是不是感到很兴奋?它看的地方应该是这个女孩而非热狗。
再比如,问题是:这个人滑雪姿势是不是正确?镜头聚焦的是整个人,这当然也正确,但如果将目光聚焦在腿部的姿态上是不是更为准确?

这也就意味着,对于现在的大模型来说,如果不把因果关系加上去,就只是在进行强行关联。幸运的情况下,这些强行关联得出的结论是正确的,否则大模型就会“胡说八道”,这是因为它背后的关联是错误的,把共生关系当成了因果关系。
共生不等于因果,经常发生的事情不一定是因果关系。
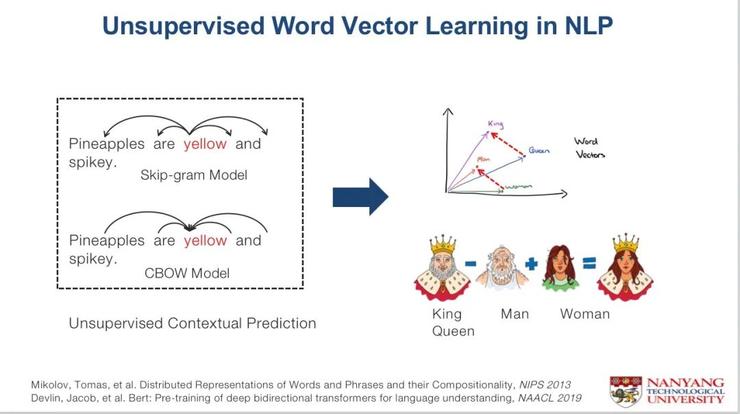
十年前,在NLP领域取得的一个非常大的进步就是词嵌入(word embedding),它的训练的方式与现在的生成式方式是一样的,就是一些文本的预测。
为什么在NLP领域用这种关联就可以学习到非常好的语义,也就是因果关系?
比如在下面这幅图中,用king减去man可以得到一种新的状态,将其加到一个性别身上,就变成了queen,这就是常识、比较有道理的因果关系,为什么会这样?
我会在后面解释更加底层的原因,这里先说一个简单问题,现在NLP整个领域濒临“灭门”状态就是因为基本上所有记录在案的symbol已经经过人类进行消化,形成因果关系了,而并非两个东西完全关联在一起。
那么在计算机视觉领域,比如在下面这张照片中,为什么耳朵会长在猫的眼睛上面,虽然可以观测到这样一种关联,但是为什么会产生这样的关联是没有记录在案的。
再比如,人用腿跑步、用腿滑雪,可以观测到人的腿与滑雪板的状态,但是人为什么用腿滑雪?背后的道理也是不会记录在照片中的。
所以说,如果只是通过照片去学习视觉特征(visual feature)的话,那么视觉的embedding与NLP的embedding相比较而言差得太多了,就只能去学习一些非常粗糙的关联。

02共因(confounder)与因果干预
研究计算机视觉的人应该都听说过MAE,即根据mask modeling这种方式来学习的视觉特征,本质上是一个非常底层的关联特征。
至于原因,这就要提到一个简单但有力的因果关系概念——混杂,也是因果干预。
混杂的模型是这样的:如果想通过物体a去推断物体b,就是将物体a放在这里会增加物体b出现概率的多少,想要找到这样一个确定的促进关系即因果关系,往往会被confounder干扰到,而这个confounder就是物体a与b之间的共因。
由于这个共因的存在,会导致就算a跟b没有直接的关系,也会被这个混杂的共因连接起来。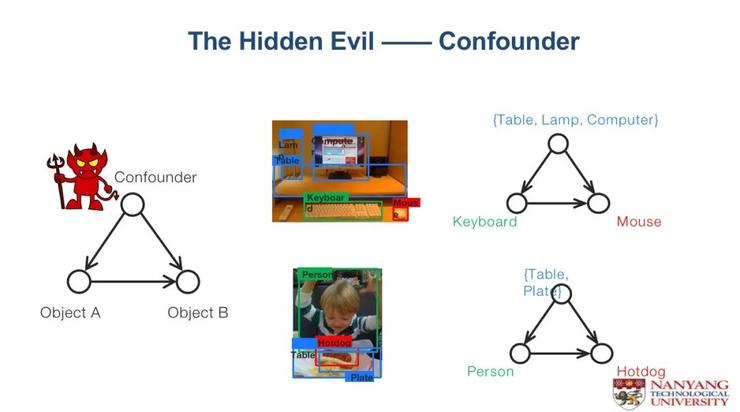
举一个非常有名的案例,如果要进行验证统计——巧克力的销量与诺贝尔奖得奖人数是强烈的正相关,但其实不是这样,它们背后有一个共因,即国家的GDP。
所以,如果想要用巧克力的销量去预测得诺贝尔奖的概率,这个是没有问题的。但是如果用它当成一种政策,让国家所有的学龄儿童每天吃一斤巧克力,那就不可行了。
也就是说,用它来做预测是可以的,但是要用它执行关乎国计民生政策上的问题,仅仅用一个预测模型是远远不够的,而且也非常危险。
再比如,想要用键盘去预测鼠标的存在,这也不可行,因为键盘与鼠标背后的一些背景共同决定了它们是不是经常在一起。所以,当你看到键盘的时候去预测鼠标的存在,可能就会发现鼠标的存在概率并不完全由键盘决定。
我们来看一些具体的例子。
下面这个图是从一个计算机视觉数据集里面统计出来的,不需要做任何模型,只需要把它的标注标签拿出来统计一下,就会发现几个比较有意思的事情。
首先是水盆与吹风机的关系——看到吹风机去猜旁边有没有水盆。如果用简单的关联去猜测,这个概率是很高的,约为0. 56。但是经过因果干预以后,发现它的概率其实是降低了。
为什么?背后的原因就在于这个数据集中,几乎所有的照片都是网上公开的酒店洗手间照片,可能是为了节省空间,酒店洗手间中吹风机与洗脸盆的放置位置一般是吹风机挂在墙上,洗脸盆在其下面。
但是仅仅因为吹风机就会导致洗手盆的出现吗?如果只根据该数据集分析,这是一件高概率事件,但是用我们的常识想一下,就会发现这不太靠谱。
第二个例子是在卫生间中,抽水马桶与人共同出现的概率经过因果干预以后反而升高了,这又是为什么?
其实还是我所强调的那个原因,在这个数据集当中,基本上马桶与人在一起共生的次数非常少,或许是出于个人隐私,不可能经常拍到一个人在上厕所,所以照片中在马桶周围基本没有人存在,就算有人,也不是正在使用马桶的场景。
但是常识告诉我们,马桶是给人用的,马桶上面坐着一个人是件合理的事情,这个才是真正“看见马桶去猜人”的因果关系,而不是单单从概率上面去判断。
所以在做了一些因果关系的调整后,其实是在概率上进行重置,也就是把一些周围的物体借过来,然后看如果周围多放一个水盆、一个杯子、一个包,把所有这些可能的东西做一个权重,加起来以后,会发现“看见马桶去猜人”的概率会提升两倍,是原来的三倍,这才是更加合理的事情。
也就是说,我们在这个数据集上可以做到一个无偏的估计去逼近真正的自然语言,就是在大量、丰富语料库的词与词之间进行word embedding这样一个更好的预测。
就是这么一个简单的因果干预,我们在过去的两到三年时间里,在这个领域进行了连续的研究,也做出了一些成果。
03因果关系在大模型中的重要性
当大模型出来以后,我们首要面临的一个问题是,原来因果关系基本上是用来做预测任务中的“去偏见”,做一些训练分布之外的工作,因为测试集与训练集的分布不一样。
但是,由于现在的模型太大了,基本上所有的测试集都是训练集的排列组合,测试的Benchmark已经不存在了,还怎么使用因果关系?因此,我们就需要进行更多深层次的思考,这也是我最近一两年在做的一些事情。这个深层次的思考可以下面这张图来说明,其实就两点:
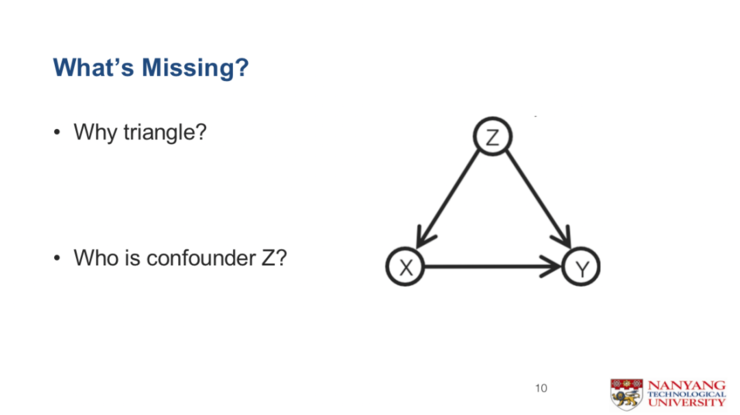
第一,为什么这张图是一个三角形的样子?以往如果要做因果关系,大家肯定会画出来这样一个三角形的假设,为什么这个假设是正确的?现在的这种假设基本都是一些领域专家自己画的,那有没有可能从数学上证明它?
第二,这个三角形的顶点,即confounder到底是什么?以往是给一个具体的任务去定义一个confounder,但其实没有共性的东西。
如果要回答这个最基础的问题,就要考虑工具,但前年年底,我们发现现在的线性代数已经不够用了,数学工具出现了问题。
类似于在微积分发明之前,基本上很难找到各大行星的运作规律,只能通过几何方式去统计它的轨道。虽然这也能做出比较好的预测结果,但是背后的原理无法知晓。
也就是说,想要发现真正的牛顿力学需要用到一些新的数学工具。我们尝试着用抽象代数中的群论概念来定义深度学习中更为深层次的东西,就是我们首先要定义深度学习在学什么。答案是深度学习其实是要去解耦它所观察到的世界。
解耦有两个数学概念可以去刻画,第一个是可拆解,或者是模块化,即一个特征中不同的位置应该负责不同的功能。
第二个是等变性,我们可以举一个比较有意思的例子来说明这一点。
十几年前,女生如果要想拍一张漂亮的照片,她应该是先化妆再去拍照,但到了现在,计算机视觉技术的特征等变性已经非常高,女生完全可以先拍一张照片,然后用Photoshop上妆。
也就是说,物理世界的化妆变化其实在虚拟世界中是可以做到等变性的。
这两个就是深度学习想要追求的一些东西,我们用群论去定义在观测里面变化的概念。
比如,在下图中,我画了一个行星轨道图来演示最本质的深度学习动力学,其实就是用群论概念重新定义什么是分类。每个轨道每一张图的转变是大家共享的一个力,对应的是大家共享一些retribute;而跨轨道的变化,就是跨类别的变化。

基于这样的重新定义,我们用这套数学语言就可以把三角形证明出来了。它的用途主要体现在两点:第一,它解释了confunder是什么,就是大家共享了一些背景;第二,我们可以用它来实实在在做一些最基础的事情。
第一个就是“去偏”,我们发现现在最流行的“去偏”方法存在bug,用基于这个图中的方法才能真正把confounder找到。也就是说,现在的一些“去偏”方法所找到的偏见也有可能是模型的缺陷,但缺陷不代表是偏见,而偏见是缺陷的一部分。我们要找的是那种很纯的偏见。
第二个是可以做一些有意思的生成,比如想让这个人去跳舞,跳舞的动作就是class,而她的身体等都是背景,当把背景和偏见等东西找到,就可以组成你想要的生成效果。

接下来是比较流行的Prompt tuning,该如何用因果关系的图去理解呢?下面是目前多模态prompt tuning一个最主要的流程,我们可以假设这个视觉特征经过像CLIP这么大的模型近似的拆分。
基于这种假设,那么Prompt tuning就是在找经过tune的prompt 应该怎样变化。其中,dog这个class是给定的,所以要去做分类的话就是在找一个合适的背景,目前流行方法存在的一个问题是训练得越多效果越差。
学过机器学习的人都知道这个是over fitting,不足为奇。但是有一些case是你给的数据越多反而效果越差,这个就比较奇怪了,如果要解释的话,完全可以用class与context不停地对抗,此消彼长的概念来解释。
接下来讲最后一点,现在大模型的特征尤其是视觉这一块的特征,存在一个问题,就是它虽然做到了可拆解、模块化,但是没法做到等变性。
如下图所示,当你用一个比CLIP还强大的大模型去计算语言和图片间距离的时候,就会发现其实这个房子从左到右慢慢的渐变过程,在语言上很难准确地让相似性变成等变性。
也就是说,语言上的“右”改成“左”,并不能够反映这个房子从左到右的变化,而不等变就表明有一些信息丢失了,所以说我们还是用群论的理念去理解。
这就像我们上面说到的,不用真正物理上的化妆,只用用PS进行化妆就可以了。用这样一种简单的方法去做一些loss上面的设计,我们就可以得到一个非常好的等变的多模态相似性。
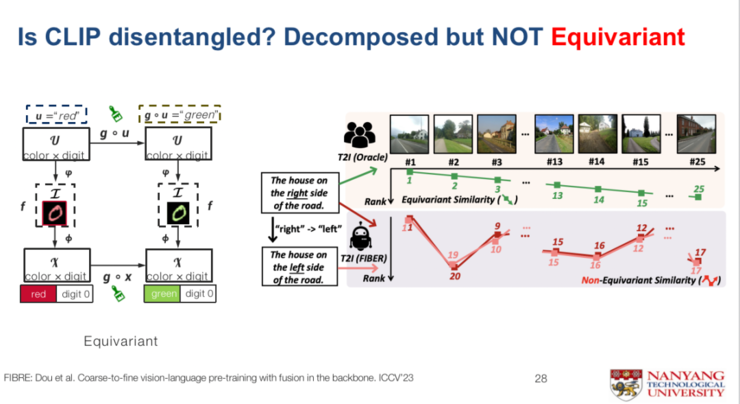
下面是我们提的一个Benchmark,如果你在训练多模态模型的话,那么就可以拿这个Benchmark去测验你的大模型是不是等变得好。

最后,我想给做大模型尤其是多模态大模型的研究者一些学术上面的建议。
第一个,我们一定要多加关注等变性,因为可拆解性是可以通过数据量堆叠实现的,但是等变性不可以,所以在预训练的时候要注意这一点。
第二,现在所有多模态大模型都会有一个问题,多模态之间互通的瓶颈在于非语言模态(例如图像)的spatial tokens和语言分布差的太远。
语言的本质是可递归的符号系统,这也是大语言模型可以推理的基础。所以,如果想得到真正的多模态大模型,就必须找到一种“可递归,可拆解的”的tokenization的方法,把非语言模态转成“可递归分布”的token。
以上就是我今天分享的内容,谢谢大家!
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!