在过去的一年里,生成式AI大模型成为了全世界范围内绝对的热点。
ChatGPT一声炮响,给全世界带来了AI革命的震撼。
从画师、模特和程序员失业危机的讨论,到大模型密集发布引爆厂商之间的“千模之战”。人工智能从未像如今这样深刻的影响着人们的生活。
自2022年11月ChatGPT推出后,短短两个月时间,活跃用户就已冲上一亿,不仅超越了Tik Tok成为有史以来增长速度最快的消费类应用,也是以人工智能为核心卖点的第一个杀手级应用。
在GPT类应用的风起云涌下,人们关于未来的畅想也如同野马脱缰。
生成式的AI模型能够基于关键词和简单的提示创造出包括文字、视频甚至程序在内的原创内容。不论是在娱乐性还是生产力方面,在人们的畅想中都毫无疑问是继移动互联网兴起之后下一波爆点,甚至是下一次技术革命的开端。
在打响了第一枪之后,大模型正在努力完成从云端走向终端,完成从技术到应用的蜕变。
大模型的普及之困
英伟达CEO黄仁勋今年3月时就高呼AI迎来了“iPhone时刻”,但实际上,生成式大模型要成AI界的“iPhone”,还要跨过从云端到终端的高墙。
熟练使用大模型的能力,已然和世纪初的“会使用电脑”、“会打字”一样,成为步入下一个科技世代的门票,甚至出现在了一些公司的招聘要求中。
ChatGPT能够出圈,除去生成式人工智能带来的新奇体验和生产力上的跨越升级,还与其简单、符合常识认知的操作有关:ChatGPT的界面与人们早已熟悉的社交软件聊天界面几乎相同,对使用者来说几乎可以从社交软件的使用经验得到的直觉中掌握用法。
但形式上的简单并不代表技术上的坦途,事实上,GPT敲出的每一行字的背后,都存在着大模型繁复的训练和推理。
与传统的搜索方法相比,生成式大模型的搜索成本高出十倍。
在键盘上敲下一次问题,等待GPT回复的短短数秒内,牵扯到云端背后数以千亿级的参数。
而受到模型本身参数规模的要求,要完成一个生成式AI模型的部署对计算设备基础设施建设提出了极高的要求。
为了满足动辄拥有数十亿参数模型的计算需求,在当前的条件下,无论是优化模型的AI训练过程还是执行模型命令的AI推理过程,目前几乎都部署在云端。
云端的强大算力固然能够满足大模型的胃口,但同时也带来了问题。
一方面,完全依赖云基础设施进行运算会带来更高的计算成本,据统计,即使基于大语言模型的搜索只占一小部分,也会在同样的搜索操作中给企业带来每年数十亿美元的增量成本。
另一方面,查询需求达到高峰时,往往会出现高延时或排队等待的情况。
事实上,由于ChatGPT的火爆,在高峰期时已经发生过拥堵。此外,要使用云端算力,需要有良好的网络环境,一旦用户在没有网络或网络环境不佳时,往往出现延时较高甚至无法连接到服务的问题。
作为厂商,要想保证用户在高峰期的使用体验就必须在云端配置足够强大的算力,这不仅带来了巨大的成本压力,也会在非高峰期造成相当的资源浪费。
而作为用户,一个可能随时请假撂挑子的不稳定因素也与期待想去甚远。
要想真正做到“无处不在”,大模型需要放下云端的高大全,走向本地终端的小而美。
AI革命烧向终端
人工智能从云端走向边缘的趋势早已不是新闻。在过去几年物联网和5G等技术的发展为AI走向边缘提供了强烈的需求。大型任务对应云端,小型任务对应边缘终端的AI部署模式已经相当成熟。
但与物联网普遍的轻载要求不同,部署在终端的大模型依然需要相当的算力。如何把庞大的大模型塞进手机、XR等终端设备中,是厂商要面对的第一大难题。
将原生的大模型直接“塞”进手机,显然是移动设备相较于云端孱弱的算力不可承受之重。
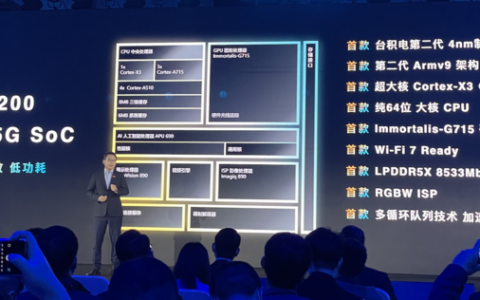
在云端服务器上训练的模型一般采用32位浮点运算,这种选择带来较高精确度的同时,也带来了较高的负载。在高通第二代骁龙8的Hexagon处理器中,就采用INT8进度实现了模型从云端到终端的迁移。
由此带来的另一个问题是,在降低数据精度之后,如何保证生成式AI的体验?
为了适应新的需求,一种为大模型设计的工作负载分级处理机制正在应运而生。
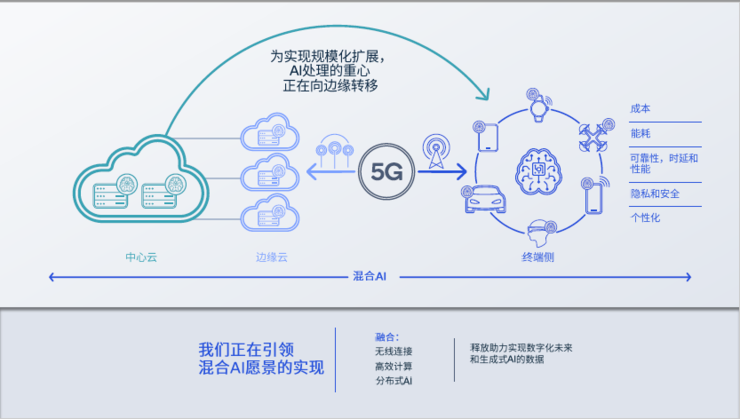
在这种分级机制中,终端将取代云端成为大模型工作的核心。在任务真正被大模型响应前,会进行预先分类。根据提示词的长度、需要调用模型的大小以及任务本身的复杂度,推理任务会被分配到不同目的地。
如果模型大小、提示词的长度和复杂度小于某个限定值,任务将会被分配在终端而不是云端进行。部署在终端的模型也许没有云端聪明,但已经足够处理这些轻度任务,向用户提供可接受精确度下的答案。
只有更为复杂的任务才会被上传至云端处理,这不仅大大解放了云端的算力,降低了部署大模型应用的成本,也为用户带来了更好的体验。在大多数情况下,用户甚至不需要联网,只需要通过部署在本地的模型就能得到想要的答案。
终端和云端也能够协作。在某些情况下,用户可以利用终端算力进行一些初步工作,在交由部署在云端的大算力进一步处理。
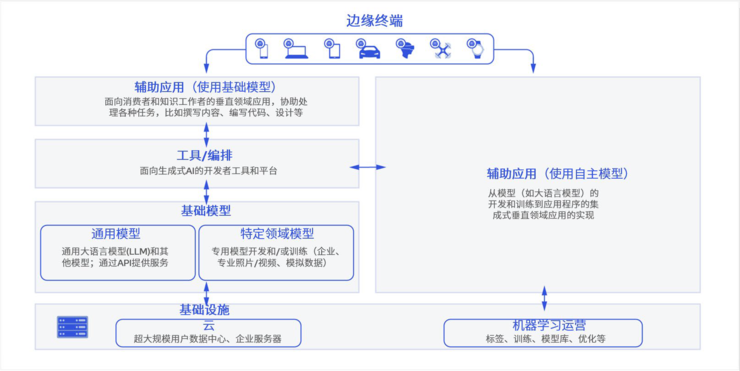
比如在使用语音和大模型对话的流程中,可以通过终端部署的本地模型完成语音识别,将语音转为文字后再上传云端,云端的大模型则用于生成对应的答案并将文本发送回终端。最后,终端再将文字答案转化成语音,与用户完成对话。
与将所有的工作负载放在云端上相比,这种工作流程能够大大节省计算和连接所需的带宽。而用户在使用过程中则几乎感受不到流程变化产生的影响。
值得兴奋的是,这并不是一种理论上的可能,而是已经投入现实中的应用。
在使用骁龙芯片的骁龙本上,生成式AI就能通过边缘与云端的协作,实现视频会议语音转录、制定任务清单、生成完整演示文稿等操作。
在老黄激动宣布“iPhone 时刻”的到来后,从云端到终端的“降维”正在让大模型真正实现的普及。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!