北京时间6月30日,MLCommons社区发布了最新的MLPerf2.0基准测评结果。在新一轮的测试中,MLPerf新添加了一个对象检测基准,用于在更大的OpenImages 数据集上训练新的 RetinaNet,MLperf表示,这个新的对象检测基准能够更准确反映适用于自动驾驶、机器人避障和零售分析等应用的先进机器学习训练成果。
MLPerf2.0的结果与去年12月发布的v1.1结果大致相同,AI的总体性能比上一轮发布提高了大约1.8倍。
有21家公司和机构在最新一轮的测试中提交了MLPerf基准测试的成绩,提交的成绩总数超过了260份。
英伟达依然“打满全场”
本次测试中,英伟达依然是唯一一家完成2.0版本中全部八项基准测试的参与者。这些测试包含了目前流行的AI用例,包括语音识别、自然语言处理、推荐系统、目标检测、图像分类等方面的内容。
除了英伟达之外,没有其他加速器运行过所有基础测试。而英伟达自2018年12月首次向MLPerf提交测试结果以来就一直完成所有基础测试。
共有十六家合作伙伴使用了英伟达平台提交了本轮测试结果,包括华硕、百度、中国科学院自动化研究所、戴尔科技、富士通、技嘉、新华三、慧与、浪潮、联想、宁畅和超微。在这一轮MLPerf的基准测试结果中,英伟达及其合作伙伴占了所有参赛生态伙伴的90%。
这显示出了英伟达模型良好的通用性。
通用性在实际生产中,为模型协同工作提供了基础。AI应用需要理解用户的要求,并根据要求对图像进行分类、提出建议并以语音信息的形式进行回应。
要完成这些任务,需要多种类型的人工智能模型协同工作。即使是一个简单的用例也需要用到将近10个模型,这就对AI模型通用性提出了要求。
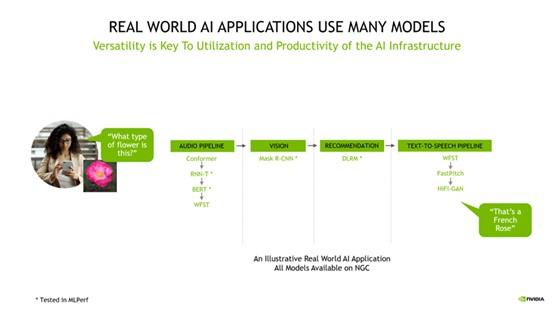
好的通用性意味着用户在整个AI流程中可以尽可能的使用相同的设施工作,并且还能够兼容未来可能出现的新需求,从而延长基础设施的使用寿命。
AI处理性能三年半提高23倍
在本次基准测评结果中,NVIDIA A100仍然保持了其单芯片性能的领军者地位,在八项测试中的四项中取得了最快速度的成绩。
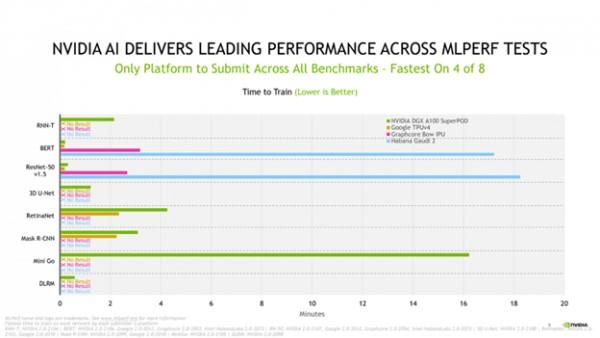
两年前,英伟达在MLPerf 0.7的基准测试中首次使用了A100 GPU,这次已经是英伟达第四次使用该GPU提交基准测试成绩。
自MLPerf问世以来的三年半时间里,英伟达AI平台在基准测试中已经实现了23倍的性能提升。而自首次基于A100提交MLPerf基准测试两年以来,英伟达平台的性能也已经提高了6倍。
性能的不断提升得益于英伟达在软件上的创新。持续释放了Ampere架构的更多性能,如在提交结果中大量使用的CUDA Graphs可以最大限度地减少跨多加速器运行的启动开销。
值得注意的是在本轮测试中英伟达没有选择使用其最近发布的Hopper GPU,而是选择了基于英伟达Ampere架构的NVIDIA A100 Tensor Core GPU。
英伟达Narasimhan 表示英伟达更希望专注于商业上可用的产品,这也是英伟达选择在本轮中基于 A100提交结果的的原因。
鉴于新的Hopper Tensor Cores能够应用混合的FP8和FP16精度的数据,而在下一轮MLPerf测试中英伟达很有可能会采用Hopper GPU,可以预见在下一轮基准测试中,英伟达的成绩有望取得更大的飞跃。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!