
编者按:2023 年 8 月14日,第七届 GAIR 全球人工智能与机器人大会在新加坡乌节大酒店正式开幕。论坛由 GAIR 研究院、世界科技出版社、科特勒咨询集团联合主办。大会共开设 10 个主题论坛,聚焦大模型时代下的 AIGC、Infra、生命科学、教育,SaaS、web3、跨境电商等领域的变革创新。此次大会是在大模型技术爆炸时代,国内首个出海的 AI 顶级论坛,也是中国人工智能影响力的一次跨境溢出。

在第一天的“GPT 时代的杰出贡献者”专场上,林伟以“ PAI 灵骏智算,为创新提速”为题发表了主题演讲。林伟是阿里云研究员、阿里云计算平台首席架构师,也是阿里云机器学习平台 PAI 技术负责人。
大模型时代 AI 工程建设是一个热门的话题,也是一个具有挑战性的问题。参数量大、计算复杂度高、需要大规模分布式集群和高性能硬件支持训练和推理,单拎出哪一点对于 AI 工程师来说都是一项巨大的技术挑战。林伟认为,随着快速变化的外界环境,如何快速训练模型,成为了模型开发的重中之重。
在演讲中,林伟介绍了阿里云 PAI 灵骏智算平台的基础架构,并从核心竞争力、平台核心基础设施建设、训练推理加速、编译技术、数据加速、RLHF 框架、平台能力和社区建设等方面,系统阐述了阿里云在 AI 工程化方面的工作进展。
以下为林伟的演讲内容,小编作了不改变原意的编辑及整理:
大家好,欢迎来到第七届 GAIR 全球人工智能与机器人大会,我是林伟,现在是阿里云机器学习平台 PAI 的技术负责人,今天我带来的分享主题是“ PAI 灵骏智算,为创新提速”。今年是 AI 大模型突破的一年,ChatGPT 让人们看到大模型的智能潜力,也推动了整个行业进入到了大模型时代。
但是训练大模型并不简单,随着模型大小呈指数级增加,如何能够快速训练模型成为模型开发的重中之重。只有通过不断地训练、反馈,以更快速度迭代,才能产生更好的模型。
我们认为,AI 的工程化和规模化是这一轮 AI 爆发的主要推动力。那么如何有效管理这些非常昂贵的超算中心,充分利用好成千上万张 GPU 算力,让算法工程师不用或者少操心系统问题,把精力更多地投入在模型构造和训练上,是我们正在关注的事情。
阿里云基于过去在大语言模型建设上的经验,推出了 PAI 灵骏智算平台,旨在提供大规模的深度训练能力,帮助用户更好地管理算力,在计算、AI of Science,以及生成式 AI 的各个方向去贡献自己的力量。今天我将主要介绍阿里云在大模型环境里下,有关架构的一些思考。
01
AI 工程化的众多挑战
AI工程面临众多挑战,其中首要挑战之一是芯片的快速迭代。平均每半年迭代一次的芯片,导致我们的计算集群呈现异构状态。在这种情况下,我们要思考如何通过调度能力和框架协同配合,将合适的任务分布到合适的资源上,并充分考虑网络拓扑。在超大规模模型训练中,网络通信是关键因素,因此合理的网络拓扑安排是确保分布式训练加速比的关键所在。
同时,我们也需要在调度中避免浪费资源,减少碎片化,以适应大模型训练的需要。在这种规模下,硬件性能已经被推至极限。大型模型的训练往往需要上千张 GPU 卡,并且在这种情况下,硬件错误、网络拥塞以及其他不可预测因素可能导致训练中断或错误。
因此,PAI 灵骏致力于为模型开发者提供帮助,使其无需过多关注这些问题,能够自动进行容错和修复。此外,还有一个重要因素是计算能力。鉴于我们的模型需要处理海量数据,如何确保计算能力不受数据传输等待的影响,从而有效供给训练过程,成为一项关键任务。
同时,分布式任务的管理也颇具复杂性,通常情况下,算法专业的同仁较难有效地优化和分布式化任务,实现存储、网络传输和调度等各个环节的均衡分配。我们需要系统深刻理解,以便在硬件资源的充分利用下,实现这些领域的平衡切割,从而解决系统瓶颈问题,为算法迭代提供坚实支持。因此,我们的AI平台需要具备更大范围的系统理解能力,以最大程度地平衡位于计算中心的资源,从而解决系统瓶颈问题,为算法的迭代提供有力保障。
02
AI 训练提效之阿里版解决方案
这张图展现了 PAI 灵骏智算平台的整体框架。最底层是阿里云的数据中心,为大数据和AI计算创造了良好的环境。在数据中心内部,拥有海量的云服务器,并配备了高速的 RDMA 网络和高性能存储设备。
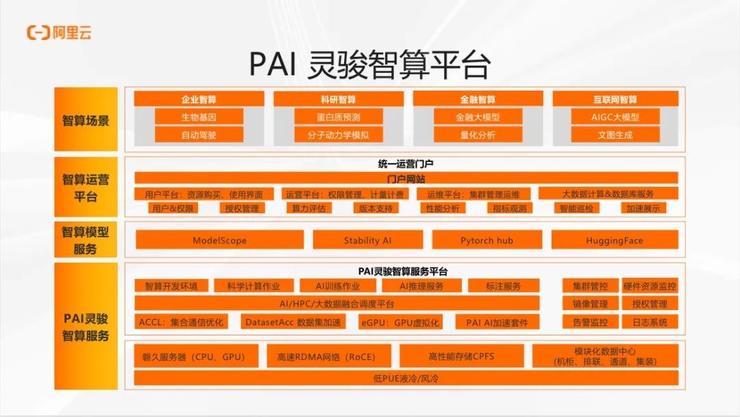
在此基础上,我们构建了机器学习 PAI 平台,它将通信、 I/O、 网络、各种芯片和已经深度优化的深度学习框架有机地结合在一起,使得算力能够高效地为上层平台和算法工程师服务,让他们能够快速有效地构建深度学习模型。
在平台上,我们还提供了模型即服务(Model as a Service)的理念,集成 ModelScope、HuggingFace 等优秀的模型库,让 AI 应用开发工程师可以在平台上构建各种有趣的 AI 应用。
从 ChatGPT 诞生后,就迅速涌现了许多 AI 应用,这也反映了一个优质的模型库和模型社区对于行业发展的重要性。我们非常欢迎学术界和产业界的同行一起加入我们的模型社区,为技术进步贡献力量。
PAI灵骏智算平台在工程上具有以下几个特点。
首先,建立了高带宽低延时的分布式 RDMA 网络,它是连接各个计算节点的关键。我们的理念是,在IB之外,我们还构建了基于以太网的 RoCE RDMA 网络。这样,才能在云上提供优质的 AI 计算平台服务,我们可以将存储等云服务和AI计算很好地结合起来,为用户提供数据治理、管理和计算等一体化的服务。
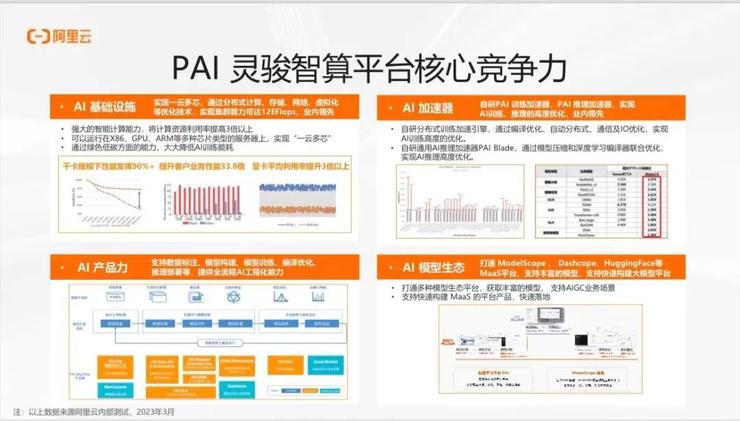
在以太网上,我们面临着更大的挑战,比如如何解决网络拥塞、通信流不均衡问题。通过自建高性能网络和通信库来解决这些问题,使得加速比能够保持在 90% 以上。如果使用普通的 TCP 网络,加速比会大幅下降。
其次,在深度学习框架方面,我们关注于引擎的后端优化,特别是在大模型时代,让算法工程师编写分布式训练代码是非常困难的,更不用说跑得好。通过自研的编译优化和自动分布式加速引擎,自动地切割模型和生成执行计划,使得我们能够很好地平衡各个节点上的 I/O、网络和计算资源,实现高效的分布式训练。在推理阶段,也可以利用编译技术,并结合模型压缩和量化技术,来适配各种多样的服务终端,从而以更经济的方式提供推理服务。
最后,在模型生产方面,PAI 灵骏提供了从数据准备、清洗到模型结构开发训练,再到模型部署的整个开发流程。在平台之上,我们还构建了模型即服务(Model as a Service)的理念,与行业内的同行一起建设模型社区,期待以模型社区激发更多的 AI 应用开发工程师进行创新和创造,构建丰富多样的 AI 应用。
继续展开来说,我们的计算平台在基础设施方面,建立了 3.2T 的高速 RDMA 网络,支持上万个节点的扩展能力,控制延迟在 1.5μs以内。我们利用多路径感知的通信库,避免集群内网络拥塞问题,实现了高性能的通信。同时,我们也做了自动的故障诊断和通信管理,保证了网络的可用性。我们已经将这个网络集成到大数据存储和计算系统中,支持 AI 的科学计算、智能计算和大模型计算等场景。
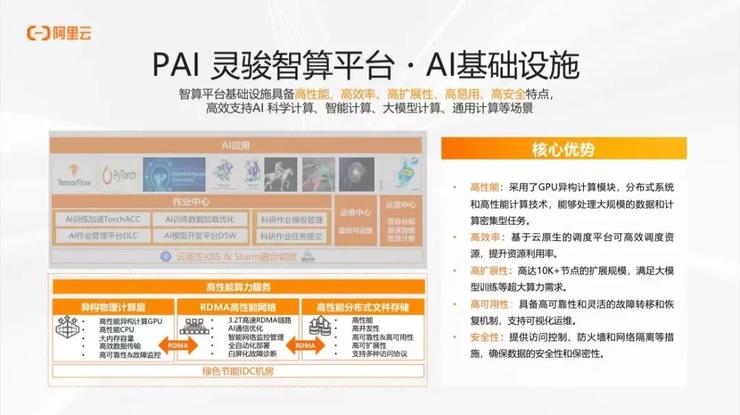
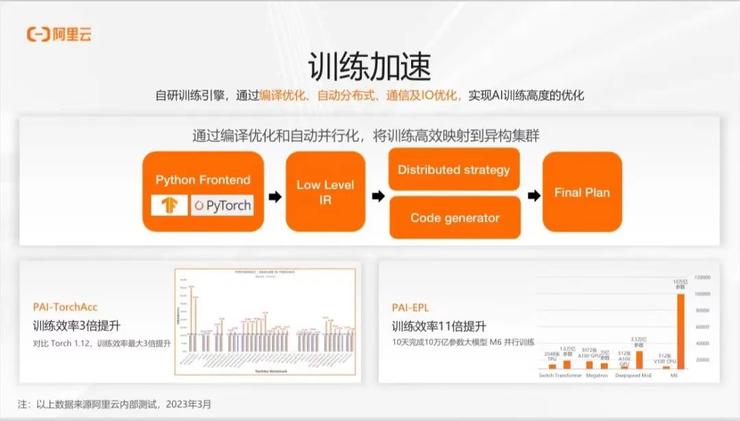
在系统层面,我们也做了很多工作来充分发挥硬件的潜能。在分布式方面,我们针对 PyTorch 推出了 TorchAccelerator 库,针对 TensorFlow 推出了 EPL 库。考虑到分布式训练的特点,我们提出了 AI Master 框架,来加强分布式环境中的调度和控制,实现弹性训练和跨高阶worker的优化。例如,通过自动容错的弹性训练,可以进行训练中节点个数的扩缩容,使得我们的分布式执行更加鲁棒。
同时,我们也聚焦于编译技术,这是优化的核心。我们通过编译过程系统地理解大模型计算的过程,让系统自动化地进行优化,选择分布式优化策略。
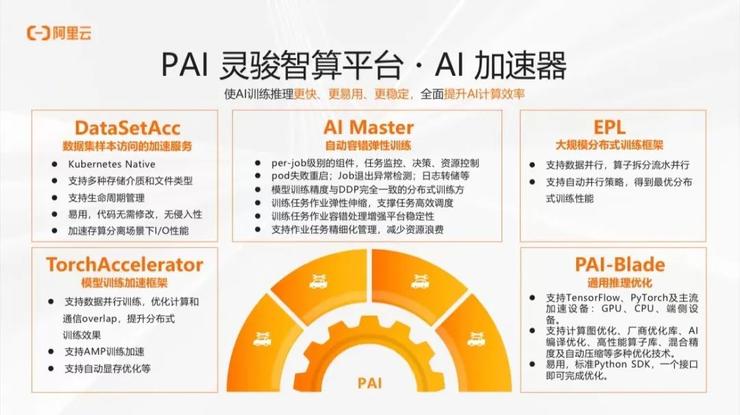
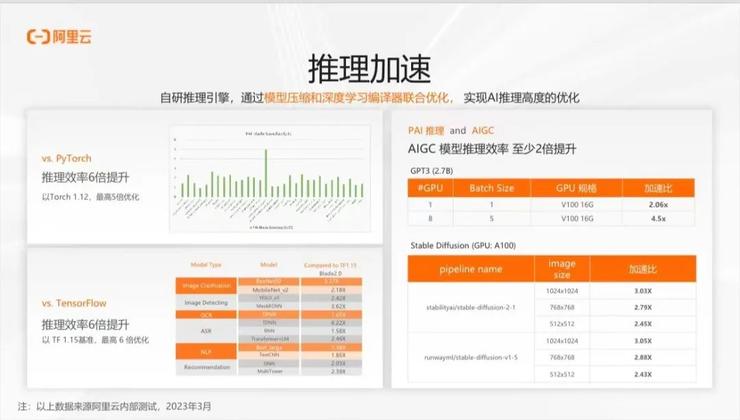
在推理场景中,我们运用混合精度、模型压缩量化等技术,并结合我们的 PAI-Blade 工具,使得用户可以以一种透明、简单的方式使用我们的自动化优化能力。
考虑到云上的数据问题,我们依托于以太网上的 RDMA 网络,将我们的PAI灵骏智算平台与阿里云的其他产品服务有机地结合起来。用户可以将数据放在 OSS、MaxCompute 等丰富的云产品中,并通过专业的数据管理系统或湖仓系统来管理数据。在训练时,我们需要快速地将数据供给计算节点,使得模型能够快速收敛。
这就带来了一个挑战:数据存在于远端的湖仓系统中,而训练算力集群又是一个高性能的智算中心。如何提高数据供给效率,并让AI 训练和推理变得更快、更易用、更稳定?
具体来说,我们的编译技术更加聚焦于后端的执行框架。在前端,不管是 TensorFlow 还是 PyTorch,我们都会将 Python 程序转译成中间语言 IR。对于 TensorFlow 的静态图,这个过程会更容易。对于 PyTorch,我们也可以通过一些方法和约束,将前端的模型表达转成 IR 的执行图。然后,我们再通过后端系统的分布式策略选择和本地代码生成,结合起来,形成最终高效的分布式执行计划。
我们这种方式可以很方便地对接各种构建深度学习的框架。我们认为,系统优化更应该聚焦于后端,因为前端是一个生态,不管开发工程师用什么样的工具构建模型,我们都能够通过我们后端的技术支持他们。现在行业里的趋势也是如此,大家在共同建设类似于 MLIR 这样的框架,并将更多的系统化优化放在后端生态系统上。可以看到,通过我们的技术,我们能够普适性地提高模型的性能,在训练上可以有不错的性能提升。
在推理方面,我们也将我们的优化技术结合在 PAI-Blade 工具中,实现了很好的效率提升。除了系统优化,我们还可以通过对模型的理解进行一些有损的优化,如模型量化和压缩,结合弹性资源,提供更高性价比的推理服务。特别是在大模型时代,推理服务的成本节省是推广模型应用的关键。希望以更普惠的方式将大模型的能力推给最终消费者。
在数据仓库的环境中,我们依托于以太网上的 RDMA 网络,所以可以很好地和云产品进行有机结合。但是,如何平衡远端的数据仓库和近端的智算中心之间的管理和性能?我们是通过 DataSetAccelerator 产品,在智算中心内部,建立一个缓存层,将远端的数据以异步的方式拉到本地的缓存中,从而有效地满足计算的需求。

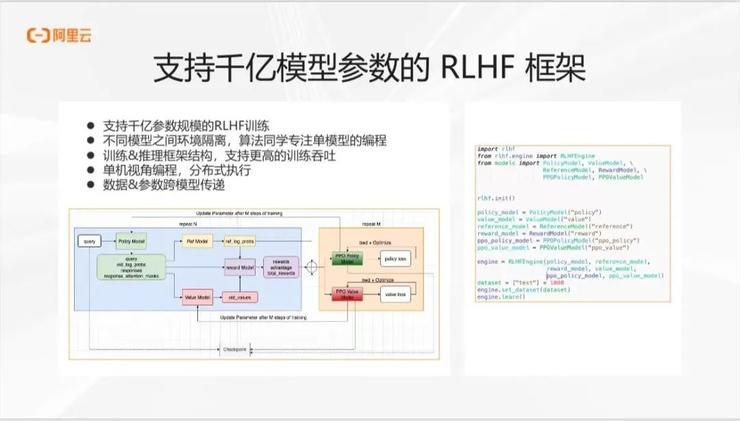
针对大模型时代的强化学习需求,我们对RLHF 的过程进行了有效的支持。我们提出了一个支持千亿模型参数的 RLHF 框架,让工程师能够更方便地构建复杂的强化学习流程,从而有效地支持模型的迭代更新。
在产品层面,我们提供了一个端到端的模型开发全过程。从数据标注到交互式建模,从大规模训练的集群管理到任务提交,从在线服务的部署到模型资产的管理,我们都提供了丰富的资源视角和任务视角,让用户可以有效地管理数据集、镜像、代码、模型和任务。我们遵循了 PaaS 层的产品理念,所有的功能都有完善的 open API,让用户可以根据自己的需求,构建自己的平台和交互方式,并将我们的能力集成进去。

除了工程和平台层面,阿里云也在推动模型即服务(Model as a Service)的模型社区建设,并且毫无保留地开放了这些年积累的模型。通过 ModelScope 魔搭社区,我们让 AI 开发变得更简单,让 AI 应用更加百花齐放,让更多的开发者加入到 AI 开发中,使得 AI 模型和应用能够更好地渗透到各个行业,为智能化开发推向一个新阶段。

ModelScope 魔搭社区和 PAI 平台进行了无缝对接,使得开发者能够更快地使用模型,根据自己的场景进行二次开发,构建自己的训练过程,并充分利用好已经训练好的大模型和预训练模型,进行二次迭代。平台也提供了一些免费的启动资源,让开发者熟悉开发环境,更便捷地进行创新。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!













