


大模型之战进入了下半场,在中国企业争先恐后抢发“自研”的类ChatGPT之后,竞争不再是从0到1的有与无之争。而变成落于实处,各家大模型肉搏,能否产生出真正的效用。
不用深度参与AI调研,大众也可以发现自然语言处理(NLP)是大模型研发最活跃的领域。在这样一个早就遍布百度、阿里以及各个研究机构厮杀气息的领域,长文本的竞争成为了一个可突破重点。
尽管有前驱者早已发展。普遍认知上国内对于大模型的关注始于ChatGPT是不争事实,近期OpenAI发布GPT-4V,使人们将目光聚焦在了多模态迁移和融合能力之上。如何对齐和超越成为一大挑战。
与此同时,在与OpenAI的竞争中,7月19日,Meta 宣布Llama 2开源,并且可直接商用,AI大模型圈一夜之间变了天,同时也宣告着大模型加速商业化时代的到来。
这场对于通用人工智能(AGI)的角逐,实际上是一场无尽的长跑、而非百米冲刺。在这样一场长跑之中,长文本与多模态的突破该如何发力,开源江湖之中,国产大模型如何一争高下?落于商业场景,哪种模式才是合适的打法?
2023年10月27日,智谱AI于 2023 中国计算机大会(CNCC)上,推出了全自研的第三代基座大模型 ChatGLM3 及相关系列产品,主要的亮点是全面瞄向GPT-4V的技术升级、模型全自研,并国产芯片适配、更开放的开源生态。
自研、国产、开源,这几个关键词加在一起形成了智谱AI的大致方向,也回答了部分我们提出的疑问。
1、中国大模型发展元年
故事,从2020年开始。
2020 年,其实并不是普遍认知上的大模型发展元年。但现在回望,事实远非如此。2020年恰是中国大模型过程中值得仔细玩味的发展元年——今日世界的泾渭分野,在彼时已伏脉千里。
这一年发生了两件典型事件:
2020 年 6 月,OpenAI 突然发布了一个超乎所有人想象的研究成果——参数规模高达 1750 亿的 GPT-3。同是预训练语言模型,但 GPT-3 的参数量是 BERT 的 500 倍,不仅能做语言生成,而且在各项语言理解类的任务上也超过了 BERT。
同年10月,中国北京,集聚了中国顶尖科技人才的智源研究院率先发起大模型项目,在此之后,发布的“悟道 1.0”是当时中国首个超大模型,再到“悟道 2.0”发布,其成为全球最大的智能模型,模型参数规模达到 1.75 万亿,是 OpenAI 所发布的 GPT-3 的 10 倍,受到了国内外的瞩目。
中美大模型技术分割之战,在这个时间节点有了新的发展方向。
成立于2019年的智谱AI的故事也与这两件事情息息相关,智谱AI多数团队成员,曾参与清华大学与智源研究院的合作项目”悟道”。
至于2020年,GPT-3的到来,带给智谱AI的与其说是影响,不如说是焦虑。
彼时,智谱CE0张鹏既震惊于GPT-3的涌现能力,也在思考要不要All in超大规模参数大模型。权衡过后,智谱AI决定把OpenAI作为自己的对标对象,投入到超大规模预训练模型的研发当中。
一个稠密的、有千亿参数规模的超级大模型,或许会带来人工智能的突破。这是张鹏坚定的信念。
但在技术路线上,智谱AI想做出的是与OpenAI不一样的事情。
智谱AI环顾四周,当时主要存在BERT、GPT和T5几种大模型预训练框架。
GPT,本质上是一个从左到右的语言模型,常用于无条件生成任务(unconditional generation);BERT则是一个自编码模型,擅长自然语言理解任务(NLU,natural language understanding tasks),常被用来生成句子的上下文表示;T5(全称为Transfer Text-to-Text Transformer )则是 encoder-decoder ,是一个完整的Transformer结构,包含一个编码器和一个解码器,常用于有条件的生成任务 (conditional generation)。
同样一份英文试卷丢给这三个模型预训练框架,GPT能通过预测下一个词来做题,通过大量写作练习来准备考试,BERT则擅长通过词句之间关系来做题,通过理解去考试,其复习资料主要源于课本和维基百科,T5则擅长将题目形式化,比如将每个文本处理问题都看成“Text-to-Text”问题 ,所有题都在一个框架下解答,具有较为强大的迁移能力。
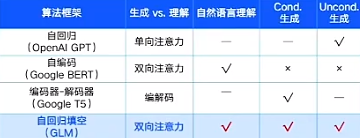
然而,没有一个预训练框架对包括自然语言理解(NLU)、无条件生成和有条件生成在内的三个主要类别的所有任务都表现最好。
GLM的思想就是想要结合以上几种模型的优点,又不增加太多的参数量。
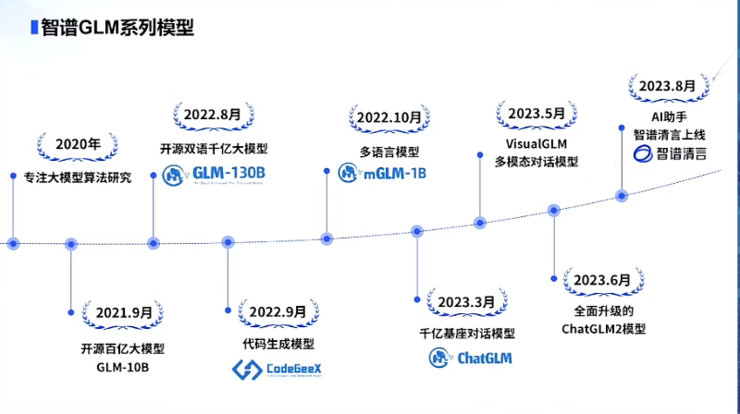
2021年9月,在团队的共同努力下,智谱AI开始了GLM预训练架构的研发,并训练了百亿参数模型GLM-10B。
技术先进,不能让商业化路途十分坦畅。
据熟悉智谱AI的行业人士告诉AI科技评论,其实智谱AI在2021年开始融资的时候,几乎没人看得懂GLM框架,也没什么人想投,智谱AI很无奈,只能开源。
如果说GLM-10B的开源是迫于无奈之举,那在GLM-130B正式诞生之后,资本市场对智谱的追捧则充分说明了整个行业对大模型的认识在逐渐成熟。
2022年8月,智谱AI推出GLM-130B。在概念上的独特性和工程上的努力使GLM-130B在广泛的基准(总共112个任务)上表现出超过GPT-3水平的性能。
值得一提的是,在诞生之初,GLM-130B就在华为昇腾芯片进行了适配训练。
很快,智谱AI身后聚集了一批知名VC。就在GLM-130B发布的第二个月,智谱AI拿到了由君联资本和启明创投联合领投的1亿元B轮融资。
在此之后,智谱AI的估值便一路高飞猛进。从2020年底的估值约 20 亿元人民币,到如今的 140 亿元,智谱AI已经成为中国估值最高的大模型创业公司。
2、大模型「上甘岭之战」
钢铁与钢铁意志的交锋,是人们对于二战中上甘岭一战的描述,这是历史上一场有名的硬战。
在经历了2022年ChatGPT引爆的生成式AI热潮以及2023年百度文心、阿里通义、华为盘古、讯飞星火、商汤日日新等30余个大模型的悉数登场之后,大模型的竞争炮火密度也到达了上甘岭之战的程度。
张鹏在多个场合引用了红杉中国关于生成式AI的观点,市场的性质正在演变。炒作和闪光正在让位于真实的价值和整体产品体验。生成式AI的下半场竞争关键是原生应用。
让大模型有应用价值,技术的突破点还可以往什么方向发展?长文本和多模态的融合似乎是这场战争中的长枪和大炮。
在ChatGLM 3 系列模型发布后,智谱成为了目前国内唯一一个对标OpenAI全模型产品线的公司:
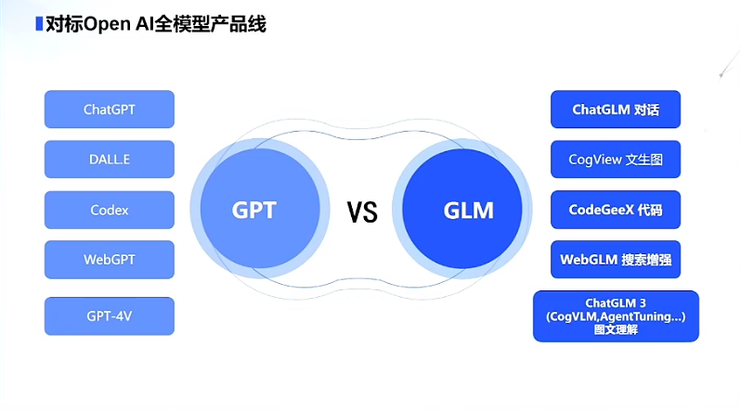
提及OpenAI全模型产品线,我们不得不提到OpenAI近期发布的GPT-4V,在视觉理解、描述、推理等诸多方面表现出了类似人类水平的能力。
据张鹏介绍,瞄准GPT-4V,ChatGLM3 实现了若干全新功能的迭代升级,包括:多模态理解能力的CogVLM-看图识语义,在10余个国际标准图文评测数据集上取得SOTA,CogVLM也被誉为“十四边形战士”。
在现场,我们也看到了ChatGLM3的看图识语义能力,丢给他一张照片,他能立马识别照片是在哪里拍摄的。
ChatGLM3代码增强模块 Code Interpreter则可以理解为让模型具备写代码的能力,能根据用户需求生成代码并执行,自动完成数据分析、文件处理等复杂任务;
网络搜索增强WebGLM-接入搜索增强,能自动根据问题在互联网上查找相关资料并在回答时提供参考相关文献或文章链接。
此外,ChatGLM3此次还推出可手机部署的端测模型ChatGLM3-1.5B和ChatGLM3-3B,支持包vivo、小米、三星在内的多种手机以及车载平台,甚至支持移动平台上 CPU 芯片的推理,速度可达20 tokens/s。在火热的Agent方面,ChatGLM3 集成了自研的 AgentTuning 技术,激活了模型智能代理能力。
既然是对标GPT-4V,ChatGLM3也不得不面临输入同一个问题,得到的答案可能是不相同的难题。因为,模型往往通过采样的方式,决定token的产出结果,而不是固定取softmax算出的最大概率token。也就是说,幻觉问题极有可能在实际操作中出现。
CNCC大会的ChatGLM3的表现也有一个小插曲,生成一张心形图片,最后变成函数图,也正是幻觉现象在作怪。
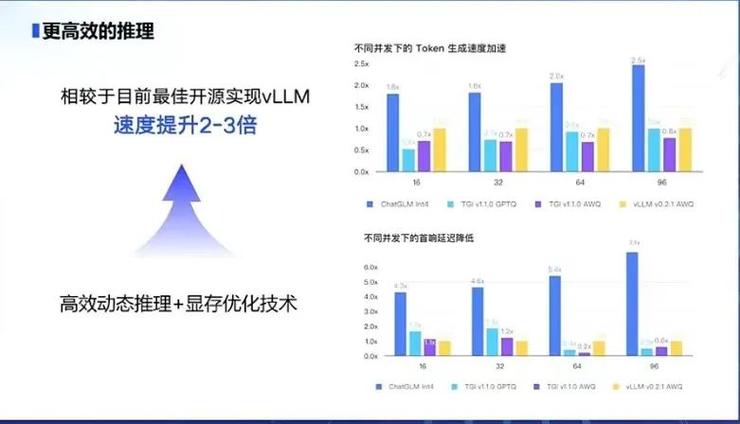
除此之外,据张鹏介绍,此次ChatGLM3的语义能力与逻辑能力也大大增强。不同并发下的Token生成速度相比其他主流开源模型如vLLM,提升2-3倍。对此,张鹏介绍道,一般而言语义数与 token 之间是1:1.8的比例关系,也就是说20 token相当于30到40个汉字,其实这也是一般人的每秒平均阅读次数。
现阶段的ChatGLM3-1.5B-Base的性能在各个评测级上已经相当于ChatGlm2-6B-Base的性能。参数下降,但是性能却明显提升,这保证了在文本处理上ChatGLM3的表现。
语义能力与逻辑能力其实是NLP领域老生常谈的话题,只不过,如今的大模型竞争,早已从注重多轮对话能力演变成了对长文本能力的追逐之中。
近期,月之暗面发布智能助手产品Kimi Chat可支持输入20万汉字,按OpenAI的计算标准约为40万token;港中文贾佳亚团队联合MIT发布的新技术LongLoRA,可将7B模型的文本长度拓展到10万token,70B模型的文本长度拓展到3.2万token。
在月之暗面Kimi Chat发布之际,杨植麟就告诉过AI科技评论,目前很多长上下文的模型走的是以下三种捷径:金鱼模型、蜜蜂模型、蝌蚪模型。
“蜜蜂模型”是关注局部,忽略了全局,虽然可以输入整个上下文,但模型可能只是采样其中的局部。比如一篇文章的关键在中间,那么它就无法提取到关键信息。“蝌蚪模型”则是能力不够,可能只有10亿的参数量,并不是千亿级别的,所以能力有限。“金鱼模型”可以理解为,以滑动窗口的方式,直接主动抛弃了很多上文,虽然号称的范围很长,但是实际上支持的很短,这种鲸鱼模型很难解决很多任务
三种模型各有利弊,暂时没有一个合适的技术模型能完美地解决所有难题,各家大模型能做的仅仅是在参数、注意力和足够的信息之间进行平衡与取舍,达到适合的范围。
算法层面各有千秋,智谱AI告诉我们长文本的突破也许可以从硬件方面下手。
此次CNCC大会,张鹏也宣布开源ChatGLM3-6B-32K。
众所周知,仅就多轮对话能力而言,开源模型和私有模型部署存在代差。目前绝大多数开源模型的上下文都只有2k,而GPT-3.5已经升级到了16k,GPT-4目前支持8K,Claude的特殊版本极限可以支持100k。ChatGLM3-6B的上下文直接提升到了32k,达到了私有模型水平。
从2k扩展到32k,ChatGLM3主要是应用了一种叫做 FlashAttention 的技术。关于FlashAttention,“FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”一文介绍,其实长文本能力的难点在于需要增加序列长度,注意力层是主要瓶颈,因为它的运行时间和内存会随序列长度的增加呈二次(平方)增加。
其实也就可以理解为一个人的阅读文本越长,注意力越不集中,耗费的精力越多,FlashAttention是从精力方面下手,利用GPU非匀称的存储器层次结构,实现了显著的内存节省(从平方增加转为线性增加)和计算加速(提速2-4倍),而且计算结果保持一致。也就是说同样的文本,因为个人精力的提升,阅读速度变得更快了。
3、开源在前,芯片在后
开源大模型的风潮,最开始是Meta烧了一把大火。
此前,ChatGPT月活刚突破1亿,Meta就立马推出LLaMA(“羊驼”);羊驼被“非故意开源”之后,基于开源模型产生的GPT平替大爆发。百川智能的Baichuan、复旦的Moss、智源的天鹰等等,不一而足。
开源的意义,对于商业,意味着什么?
这个问题从Meta发布Llama2之后微软的反应可以看出端倪,在7月19日Meta正式发布首个开源商用大模型Llama2后,原本和OpenAI拥有长期、深入合作的微软成了Llama 2的「首选合作伙伴」,该大模型将通过微软云Azure分发。
敌人的敌人便是朋友,技术开源从某种程度上来说是撬动商业蛋糕最好的手段。
2023年,智谱AI选择将单卡版模型ChatGLM-6B进行开源,供研究者与个人开发者们进行微调和部署。
ChatGLM-6B的受欢迎程度是意料之中的,多位开发者曾公开评价,相对于LLaMA-7B、BLOOMZ-7B1等同类模型来说,ChatGLM-6B裸测中文效果最好、模型参数量更小(62亿),国内开发,具有本土优势。
数据显示,智谱AI的开源模型在全球下载量已超过1000万次,其还针对不同应用场景,开发出了生成式AI提效助手智谱清言以及高效率代码模型CodeGeeX等AIGC模型及产品。
而具体至中国的语境,开源的意义,意味着什么?
这个问题则可以用芯片领域著名的RISC-V来回答,由英特尔和ARM公司主导的芯片架构领域,X86和ARM几乎处于垄断地位,架构存在不授权或不供应等风险的大背景下。在此种情形之下,开源的RISC芯片架构项目,其发起初衷便是可以被自由地用于任何的地方,允许任何人设计、制造和销售RISC-V芯片和软件。
由于具备开源开放的特性,RISC-V架构也因此被国产厂商看作是国产芯片弯道超车的机遇。
放至大模型领域,在OpenAI闭源的情况下,大众对于开源的需求与日俱增,而在可以选择又必须选择国产的情况下,智谱AI成为了最佳选项之一。
2023 中国计算机大会(CNCC)上,智谱CEO张鹏表示多模态CogVLM-17B已开源,它在10个多模态榜单中排名第一。
智能体AgentLM能让开源模型达到甚至超过闭源模型的Agent 能力。
除此之外,张鹏还强调了全面适配国产硬件生态,正如前文所提,早在130B阶段,GLM-130B就适配了华为的芯片,如今用华为芯片推理速度提升超3倍。
对智谱AI而言,在大模型竞争之中,算力是一个制约发展的重要因素。情况非常复杂,变化很快,影响也很大。推进国产化芯片适配是很有必要的。
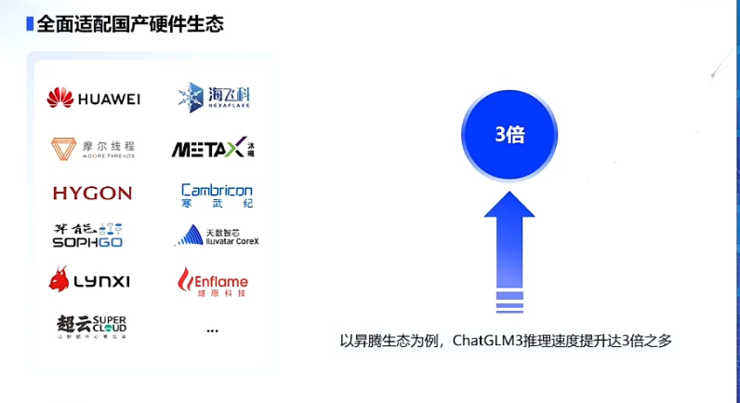
对于整个国内环境而言,智谱AI 目前是国内唯一全内资、国产自研的大模型企业,适配国产芯片,能让智谱面对不同类型的用户不同类型的芯片提供不同等级的认证和测试,这意味着智谱AI 的大模型是安全可控的,这也将直接反哺智谱AI 的商业化能力。
这也是为什么智谱如今融资十分快速的原因。
而在全面生态上,目前智谱 AI GLM大模型已经应用于政务、金融、能源、制造、医疗等领域,支持昇腾、神威超算、海光DCU、海飞科、沐曦曦云、算能科技、天数智芯、寒武纪、摩尔线程、百度昆仑芯、灵汐科技、长城超云10余种国产硬件生态,合作伙伴包括阿里、腾讯云、火山引擎、华为、美团、微软、OPPO、海天瑞声等数十家公司。
4、国产大模型围剿「GPT」之后
前段时间,在家电领域出现了关于国产吹风机的讨论。最核心的声音在于戴森之前无国产吹风机。这句话并不是指的对戴森这一品牌的吹捧,而是对中国家电行业的现状反思。
为什么中国造不出戴森,这个命题放在中国的很多行业都可以成立。为什么中国没有苹果、特斯拉这样的领头羊企业,这个疑问放到大模型领域,则变成了为什么中国没有OpenAI?
在大家都不是OpenAI的情况下,智谱AI始终追求对标OpenAI,张鹏也表示,智谱AI只会也只能和OpenAI和过去的自己比较。
从全局视角来看待,早在19年就成立的智谱AI在自我发展的过程中碰上了OpenAI,OpenAI给所有中国企业或机构都上了一课,如今,他却是最有可能与OpenAI对标,走出一条独属于中国大模型自主之路的企业。
历史的有趣之处在于,它并不是由单一因素推动发展,而是由各个不同要素叠加在一起,无数偶然所演变成的必然。当一个国家全力推动国产、一种技术源于国产、一家公司又能做成国产。
三者的命运交相辉映,一段历史的注脚就此产生。
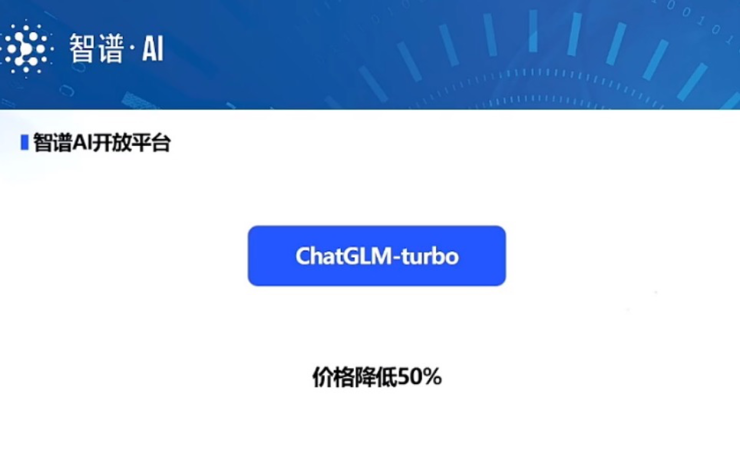
在前文,我们已经讨论过智谱AI在国产化上的布局,而具体至商业落地,张鹏在CNCC大会表示智谱开放平台ChatGLM-turbo价格降低了50%,这似乎回到了故事的开端,大模型的涌现能力让众人诧异,但高居不下的成本让人望而却步,一个无法面向全人类的产品,性能再完美,商业落地也会存在瑕疵。
而这份瑕疵,却恰恰是智谱AI与一众国产厂商最应追求的完美之处。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!