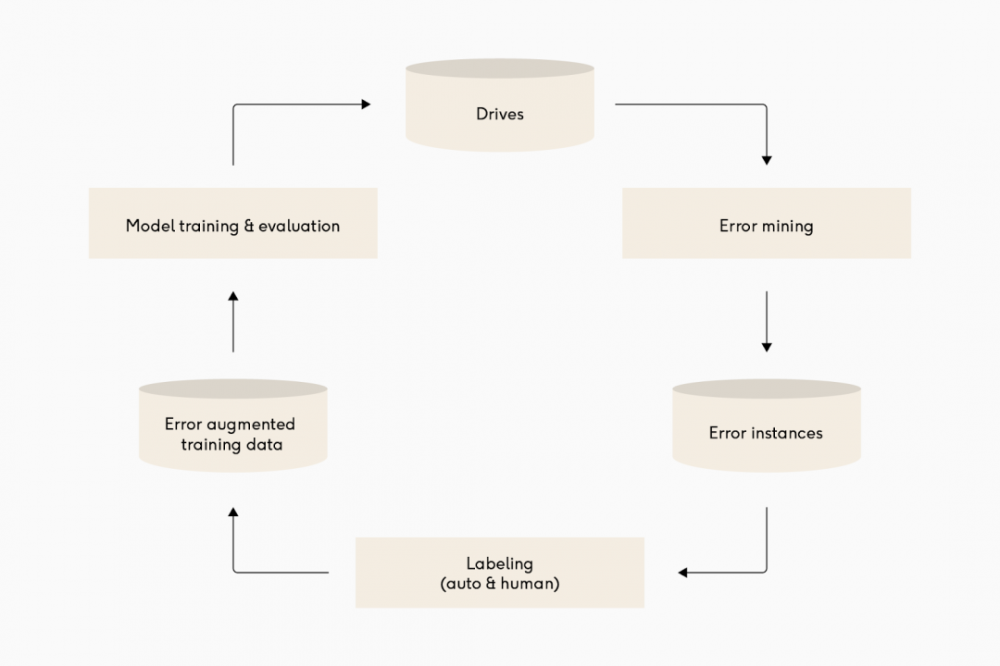
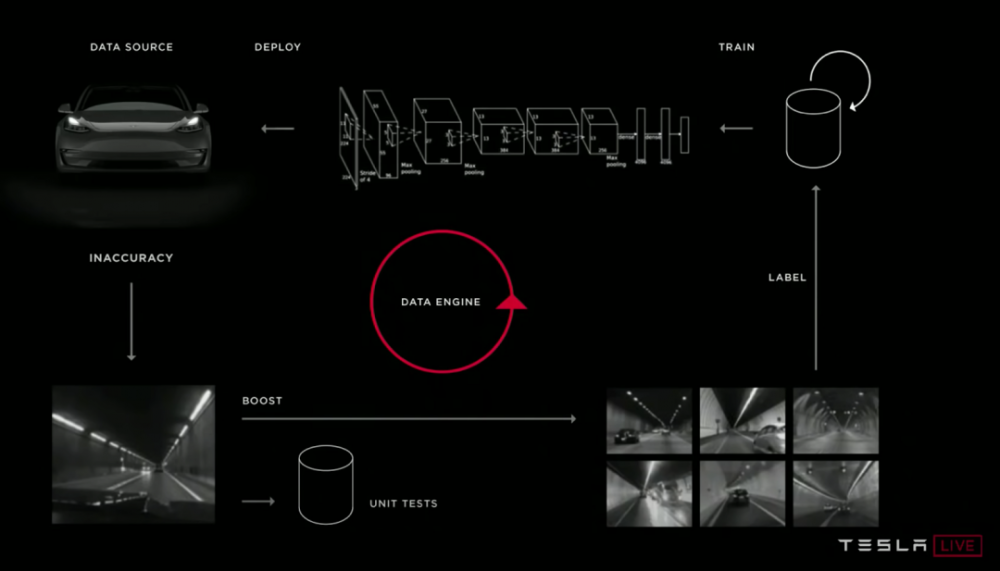
-
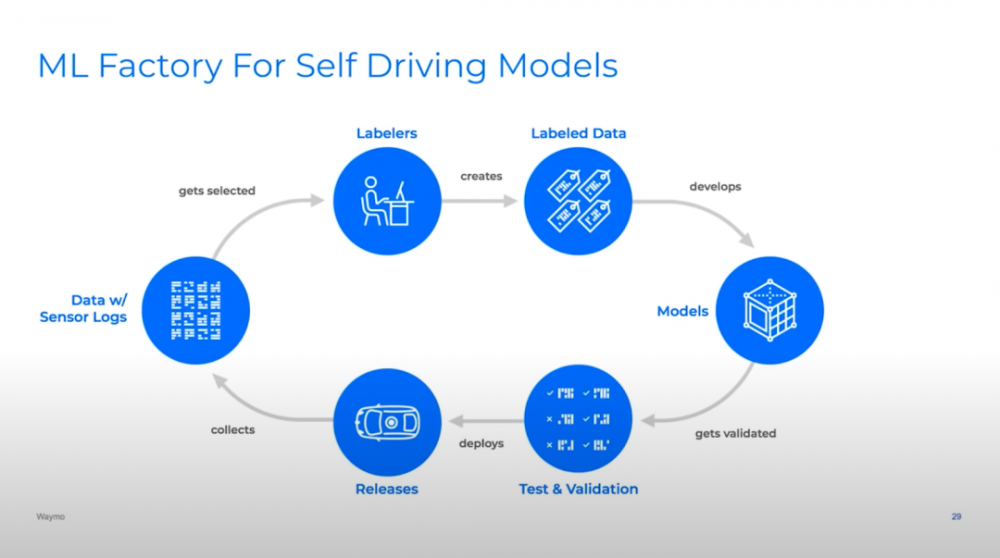
发现数据或模型性能中的问题
-
诊断问题发生的原因
-
改变数据或模型代码以解决这些问题
-
验证模型在重新训练之后变得更好
-
部署新模型并重复


-
以规律的节奏运行模型管道,并专注于比以前更好的运输模型。每周或更短的时间内获得一个新的改进型号投入生产!
-
建立一个良好的从模型输出到开发过程的反馈回路。找出模型在哪些示例上做得不好,并向您的培训数据集中添加更多的示例。
-
自动化管道中特别繁重的任务,并建立一个团队结构,使您的团队成员能够专注于他们的专业领域。特斯拉的Andrej Karpathy称理想的最终状态为“假期行动”。我建议,建立一个工作流程,让你的机器学习工程师去健身房,让你的机器学习管道来完成繁重的工作!
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!