大数据时代的隐私泄露如达摩克利斯之剑,高悬在每个网民头上,而关于如何保护数据隐私我们也走了很长的路。
1977 年,统计学家 Tore Dalenius 给出关于数据隐私的严格定义:攻击者不能从隐私数据里获取任何在没有拿到数据之前他们所不知道的个人信息。
2006 年,计算机学者 Cynthia Dwork 证明上述定义的隐私保护是不存在的。有一个直观例子可以帮助理解:假设攻击者知道 Alice 的身高比 Lithuanian 女性平均身高高 2 英寸,这样攻击者只需要从一个数据集里获得 Lithuanian 女性身高平均值(在接触数据前攻击者并不知道),就能准确获得 Alice 的精确身高,甚至 Alice 都不需要在这个数据集里。因此,对于一份有信息量的数据,不可能完全不暴露隐私信息。
2018 年,史上最严苛的个人隐私保护法案《通用数据保护条例》( GDPR )正式生效,开创了互联网诞生以来的最大变革,数据隐私问题得到前所未有的重视。
近日,第四范式先知( Sage )企业级 AI 平台已经完成 PrivacySeal EU 认证工作程序,率先通过欧盟 GDPR 认证,成为国内第一款通过该认证的 AI 平台产品,实证基于第四范式隐私计算技术的数据安全性和可信任性,那么,他们是如何保护用户隐私安全的?
匿名化或许是个伪命题?
不知道有多少童鞋记得去年谷歌母公司 Alphabet Inc 因违反隐私数据法被罚款 5000 万欧元的事情,据说这是迄今为止欧洲范围内,一家公司因违反隐私数据法遭受到的最高额处罚金。多家英文科技媒体报道时,都用了 “record high”(破纪录地高)描述处罚力度之狠。
为什么谷歌会受到如此严重的惩罚?
首先,谷歌会收集自家相关应用和第三方网页访问的活动数据,通过安卓设备的“设备标识”以及“广告标识符”,将应用数据上传至谷歌服务器,并与用户的谷歌账户关联,形成了完整的闭合。简单来说,谷歌通过被动方式收集的所谓“匿名数据”与用户的个人信息相关联 ——绕了一大圈,最后大费周章用“合法手段”应用用户信息。
同样地,Google Ad Manager 的 Cookie ID(跟踪用户在第三方网页上的活动缓存信息)是另一个据称是“用户匿名”标识符。如果用户在同一浏览器中访问Google应用程序,Google 可以将其连接到用户的 Google 帐户之前访问过第三方网页。
换句话说,虽然通常在用户匿名的情况下收集信息,但 Google 明显拥有利用从其他来源收集的数据来对此类集合进行去匿名化的能力。
Google 之所以出现这类问题,主要源于其产品在数据流转及应用上不严谨所致,同时,一些常规匿名化手段的技术缺陷同样不容忽视。
而谷歌的广告业务几乎覆盖了 90% 全球用户,200 万个主流网站,也就是说不经意间我们的生活已经被谷歌的 “数据操控” 看了个清清楚楚明明白白。
2010 年,个人隐私律师 Paul Ohm 就曾在 UCLA 法律评论中刊文指出,虽然恶意攻击者可以使用个人身份信息(如姓名或社会安全号码)将数据与个人身份进行关联,但事实证明,即便只拥有那些不会被归类为“个人身份信息”的信息,他们也可以达到同样的目的。
Ohm 参考了 Sweeney 早期的一些研究,她发现 1990 年美国人口普查中有 87% 的人可以通过两条信息进行唯一识别:他们的出生日期和他们住址的邮政编码。Ohm 还引用了 Netflix 以及其他有关数据泄露的案例,并得出结论:在传统的以个人身份信息为保护重点的匿名化技术下,几乎任何数据都无法实现永久的完全匿名。
链接攻击、同质化攻击等方式都可能从匿名化数据中定位个人身份。例如链接攻击,通过数据的半标识符在其他能找到的表上进行查询,则可能找到对应的身份定位标识符以及其他敏感信息。
2013 年,研究人员发现位置数据具有高度的独特性,因此更加难以匿名化。许多匿名数据库都可能间接泄露你的位置,例如刷卡消费或前往医院就诊。研究人员发现,通过每小时记录4次手机连接到的信号发射塔,就可以对 95% 的设备进行唯一识别。如果数据更精细( GPS 跟踪而不是信号发射塔,或者实时采集而不是每小时采集),匹配则会变得更加容易。
于是,大家开始意识到“匿名化”这东西并没有那么安全,我们的信息还是会被窃取。
所以,一向注重用户隐私的苹果在 2016 的开发者大会上提出了“差分隐私(Differential Privacy)”的概念。即通过算法来打乱个体用户数据,让任何人都不能凭此追踪到具体的用户,但又可以允许机构成批分析数据以获得大规模的整体趋势用于机器学习。将用户隐私信息储存在本机而非云端也是苹果保护用户隐私的方法之一。例如 Face ID 面容信息、Touch ID 指纹信息等都存储在 iPhone 的芯片上。
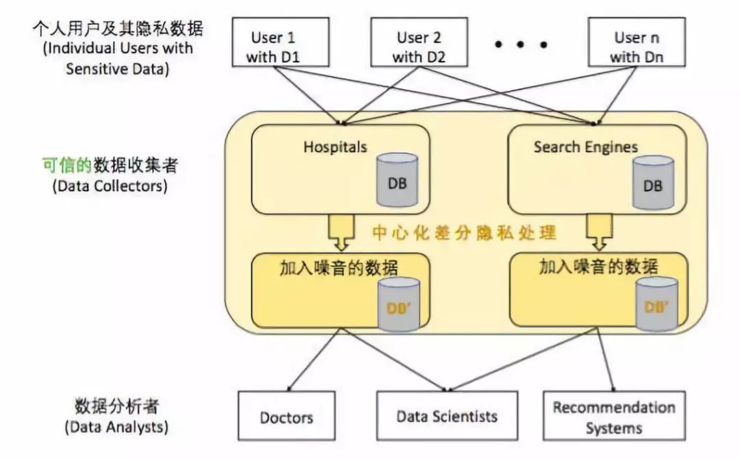
不过,差分隐私还是无法避免多个相关数据上报而导致的隐私泄露。更何况,道高一尺魔高一丈,匿名方法推陈出新的同时,攻击者们也会采用更为强力的识别工具。
那么,第四范式推出的差分隐私又是如何做的呢?
机器学习中的隐私保护
据涂威威介绍,目前已有差分隐私机器学习算法上的工作,往往是通过往训练过程内注入噪声来实现差分隐私。
常见的有三种:目标函数扰动(objective perturbation)、输出扰动(output perturbation)、梯度扰动(gradient perturbation)。常见的机器学习算法,以最简单的 logistic regression 算法为例,已经有成熟的差分隐私算法,以及隐私保护和学习效果上的理论保障。然而就目前的方法以及对应的理论来看,对于隐私保护的要求越高,需要注入的噪声强度越大,从而对算法效果造成严重负面影响。
为了改善上述问题,第四范式基于以往 Stacking 集成学习方法的成效,将 Stacking 方法与差分隐私机器学习算法相结合。Stacking 需要将数据按照样本分成数份。并且提出了基于样本和基于特征切分的两种 Stacking 带隐私保护的机器学习算法。
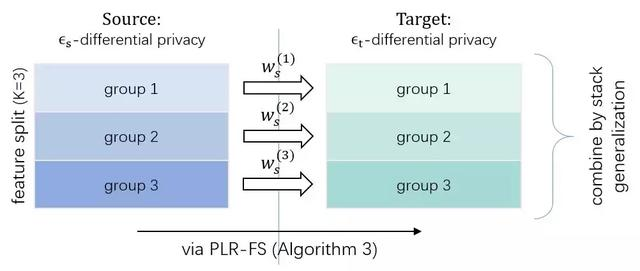
在该算法中,数据按样本被分成两份,其中一份按特征或按样本分割后在差分隐私的约束下训练 K 个子模型,并在第二份上通过差分隐私机器学习算法进行融合。
按特征切分相比过去的算法和按样本切分算法有更低的泛化误差。同时,按特征切分有另一个优势,如果知道特征重要性,第四范式的差分隐私算法可以将其编入算法中,从而使得重要的特征被扰动的更少,在保持整体的隐私保护不变的情况下,可以得到更好的效果。
此外,还可以直接拓展到迁移学习上。即在源数据集上按照特征切分后得到带隐私保护的模型,通过模型迁移,迁移到目标数据集上并通过 Stacking 进行融合。在这种情况下,源数据可以在不暴露隐私的情况下输出模型帮助目标数据提升学习效果,而目标数据也可以在保护自身数据隐私的约束下训练模型。
不过,值得注意的是,以差分隐私为代表的隐私保护技术仍需要在理论、效果、应用、成本等方面进一步解决和优化。
涂威威介绍说:“比如,在成本方面,核心的问题其实是人力。机器学习已经是很复杂的技术,落地需要很专业的人才。当前的隐私保护技术使用门槛较高,在保护隐私的前提下,多方联合数据建模的常见做法依然需要比较多的专家人工介入到数据预处理、特征工程、模型调参当中,因此落地的人才门槛更高。且人力的介入又会给数据安全与隐私保护带来一层隐患。”
因此,在差分隐私的基础上,又衍生出了另一种保护隐私的自动多方机器学习技术。第四范式综合了差分隐私技术、自动化机器学习技术,让机器自动完成数据预处理、特征工程、模型调参等工作,大幅减少了专家人工的介入,一方面进一步提升了安全性,另一方面也大幅降低了隐私保护技术的使用门槛,使得广泛落地成为可能。该技术也将是保证技术规模化落地的关键。
最后,提醒大家,虽然在隐私和便利面前,我们都抓秃了头,但不代表这就没法解决了。
电影《绝对控制》中有一句话:“隐私不是公民权,而是特权”;隐私本应是每个公民最基础的权利,只不过在过去的很长时间中,我们从未意识到行使这项权利,以至于隐私竟变成了“特权”,不过庆幸的是隐私权正在回归,人们正在拾回分散在互联网中的隐私。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!