有人说,不同言语之间的翻译,与其说是一门科学,不如说是一门艺术。
NLP 范畴的机器学习工程师 Riccardo Di Sipio 日前提出了一个观念:运用卷积网络要比运用循环神经网络来做 NLP 研讨,要美好得多——是时分抛弃循环神经网络了!
依据这一观念,他从卷积网络自身的根本原理动身,论说了为什么 NLP 不再需求循环神经网络的原因。
咱们来看:
不久前,人工智能科学家侯世达(Douglas Hofstadter) 就在 The Atlantic 上宣布的一篇论文中指出,现在机器翻译尚处于「浅陋」的阶段。
文章阅览地址:https://www.theatlantic.com/technology/archive/2018/01/the-shallowness-of-google-translate/551570/
尽管机器翻译存在局限性,但难以否定的是,主动翻译软件在许多情况下都有杰出的作用,而其背面的技能在任何存在信息从一个范畴流动到另一个范畴的语境中都具有广泛的运用,例如基因组学中从 RNA 到蛋白质编码的翻译进程。
直到 2015年,序列到序列的映射(或者说翻译)运用的首要办法都是循环神经网络,特别是长短期回忆(LSTM)网络。
我在前一篇文章中介绍了这些网络架构的基础知识,我还谈到了 LSTM 被运用于大型强子对撞机的顶部夸克对衰变的运动学重建进程。这篇文章链接如下:
然后,呈现了一些新的办法:比方残差网路架构和注意力机制的提出,为针对这类使命的更通用的结构的完成铺平了路途。
值得一提的是,这些新颖的网路架构还处理了另一个问题:事实上,因为 RNN 固有的时序性,很难运用这种网络在像 GPU 这样的并行体系上进行练习。而这一点正是卷积神经网络运用起来十分便利的当地。
一、卷积神经网络
在数学中,卷积表明的是当函数 f 作用于另一个函数 g 时生成第三个函数的一种运算:
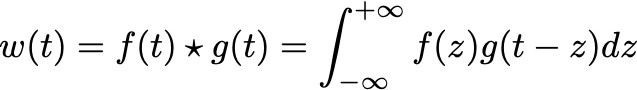
此运算不应与调制(例如 AM 传输中的 EM 信号)混杂,调制是将两个函数简略相乘。求知欲强的人可能会深究到:时刻空间中的卷积傅里叶改换,实质上是频率空间中的调制,即:
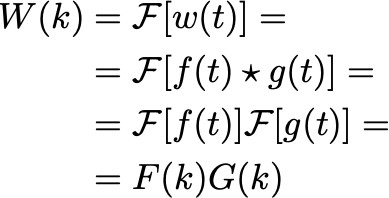
所以这两种运算尽管密切相关,但切不可被混杂。
在核算机科学的离散国际中,积分被求和替代,两函数之间的乘法由矩阵间的乘法替代。用行话来说,就是将卷积核运用到图画上来生成卷积特征,一次卷积将生成一个新的特征。在下面每一对图画中,当对左面部分发作一次卷积改换,将于右边部分发生一个新的值,如下图所示:
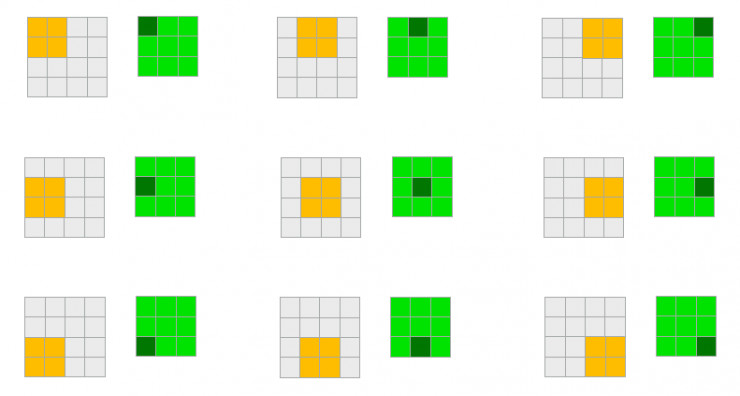
在对这个序列的操作中,图画(灰色矩阵)由一个卷积核(橙色矩阵)卷积操作以取得卷积特征(绿色矩阵)。
一般来说,卷积核是一个网络的权值矩阵,有必要经过某种算法(如:反向传达)核算,才干得到它的希望输出。
这种操作的一个很好而且很重要的特性是,一旦「图片」被加载到回忆中,不同的卷积核会对其做相关操作,这样就能够大大削减输入/输出(I/O)次数,然后更好地运用带宽。一般,卷积操作由以下两种办法履行:
- 降维:这正是上图中的比如,例如将 4×4 图画被 2×2 卷积核降维至 3×3 图画,这称为有用填充。
- 维数坚持不变:在这种情况下,在运用卷积核之前,原始图画用其周围的零来进行填充。例如,一个 4×4 图画被填充到5×5 矩阵中,然后被一个 2×2 卷积核核进行卷积操作后缩小为4×4 图画(原巨细)。这称为相同的填充。
在卷积之后,一般会进行池化操作:在每个卷积块中,只将最大值传递到下一层。此操作用于下降图片维数以及过滤噪声。降维的关键是经过信息压缩来寻觅更高水平的特征。
常用的做法是,经过将上述两个进程的板块链合在一起,来构建一个卷积神经网络。一些成功的网络架构事例如下:
- AlexNet(2012):该网络共包含 8 层;其间前 5 层是卷积层,其间一部分卷积层后边连着最大池化层,最终 3 层为全衔接层。这个网络运用 ReLU 而不是 tanh 或 sigmoid 作为激活函数。
- VGGNet(2014):望文生义,这是一个十分深的卷积网络,它总共包含 16 层。与 AlexNet 相似,它仅有 3×3 卷积核,但有许多滤波器。它是现在用于从图画中提取特征的最为干流的办法。
- GoogLeNet(2014):这个网络的创意来源于较为长远的 LeNet,但在其基础上又运用了 Inception 模块。在引进它之前,CNN 仅仅经过将卷积层叠得越来越深来完成。为阐明在相似图画中信息能够在不同标准范围内传达,该网络在同一层上运用几种不同巨细的卷积核(如:1×1、3×3、5×5…),然后将它们的输出衔接,再把九个相似上述的模块堆叠起来。因为深度网络遭到梯度消失问题的影响,更新的完成运用的是残差网络架构。
- ResNet(2015):残差神经网络具有明显的批量标准化(Batch Normalization)和跳动衔接特征。跳动衔接指的是网络中的信息经过越过某些层走捷径。这儿的「技巧」是经过残差块取得的。别的一种相似于残差网络架构的办法被称为高速公路网络(Highway Networks)。
二、注意力机制
已然现在咱们已了解了卷积神经网络的根本知识,那么让咱们回到最原始的问题:咱们怎么运用这样的网络替代循环网络来解析序列呢?
注意力机制背面的首要观念是,网络应该找出输入序列的哪些部分或元素与生给定的输出序列元素具有更强的相关性。它经过为每个输入元素创立一个注意力权重向量(权重介于 0 和 1 之间,经过 Softmax 发生),并运用它们来调整信息流。假如咱们首要重视依据 RNN 的网络,这将变得更简略了解。
关于每个输入元素(时刻阶),RNN 层会存储一个躲藏状况。所以关于 N 个输入将会有 N 个躲藏状况。此刻,咱们咱们能够经过简略地让注意力权重和躲藏状况逐一元素相乘(也就是哈达玛积)。来生成剩下文向量:
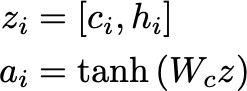
例如,当翻译一个句子时,两种言语的专有名词都是相同的,因而相应的权重会十分大(例如 0.95)。相邻单词的权重很可能十分大的(例如 0.55),而相距较远的单词权重则较小(例如 0.05)。
最终,信息被压缩成一个注意力向量,并传递到下一层:
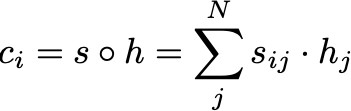
在解码阶段,则回为每个输入的词核算上下文向量。
三、Transformer 网络
现在咱们根本把握和了解了关于怎么在机器翻译中脱节 RNN 网络的一切要素。
Transformer 网络运用注意力机制,但这次运用的是前馈网络。
首要,输入序列被嵌入(即被编码成 N 维空间中的一个数字)向量作为弥补,该向量盯梢每个单词相关于互相的初始方位。现在咱们有了序列中一切单词( K)和一个给定单词( Q)的向量表明。
依据这些资料,咱们咱们能够像曾经那样核算出注意力权重(d_k 代表了维度,它是一个标准化因子):
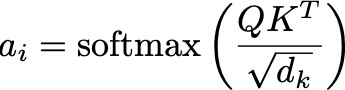
这个注意力权重决议了其他每个单词关于给定单词的翻译成果的奉献程度。
将这些权重作用于待翻译的给定序列(值V)的进程称为缩放的点积注意力( Scaled Dot-Product Attention)。
多头注意力是一种注意力机制的兼并办法,被用来将 Q、K 和 V 线性映射到不同维度的空间中。其思维是,不同的映射能够别离从不同方面杰出信息编码的办法。其间映射是经过将 Q、K 和 V 乘以练习进程中学习到的矩阵 W 来完成的。
最终值得一提的丢失,在论文《Attention Augmented Convolutional Networks》中,作者提出了一种具有多头注意力机制的 CNN ,该论文链接如下:
而以上,就是为什么咱们不再需求循环神经网络的原因~
via: https://medium.com/swlh/attention-please-forget-about-recurrent-neural-networks-8d8c9047e117
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!