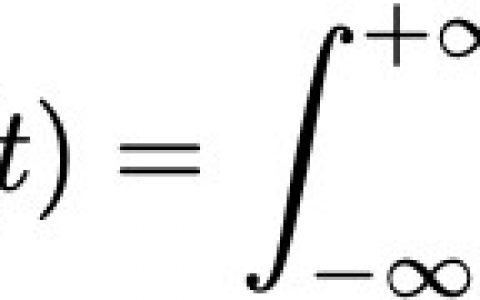2019 年,可谓是 NLP 发展历程中具有里程碑意义的一年,而其背后的最大功臣当属 BERT !
2018 年底才发布,BERT 仅用 2019 年一年的时间,便以「势如破竹」的姿态成为了 NLP 领域首屈一指的「红人」,BERT 相关的论文也如涌潮般发表出来。
2019 年,是 NLP 发展史上值得铭记的一年,也当之无愧的「BERT 年」。
NLP、ML 研究者 Natasha Latysheva 基于自己搜集的169 篇 BERT 相关论文,对 BERT 2019 年的发展进行了回顾。
我们跟随她的脚步来看:
2019 年是 NLP 发展历程中具有里程碑意义的一年,从阅读理解到情感分析,针对各大重要任务的解决方案都迎来了新的记录。
其中最为突出的研究趋势是迁移学习在 NLP 的应用,即在特定的语言处理相关任务中,运用大量预训练模型对它们进行微调。在迁移学习中可以重新使用预构建模型中的知识,提高模型的性能和泛化能力,同时大量减少具有标签的训练样本。
实际上,类似迁移学习这种先对模型进行预训练再对特定任务进行微调的方式,并不少见,比如计算机视觉研究人员通常使用大型数据集(如 ImageNet)上预训练好的模型。 NLP 领域长久以来,则一直通过重用词嵌入来进行「浅层」迁移学习。
但在 2019 年,随着 BERT 等模型的出现,我们正真看到了 NLP 领域转向更深度的知识迁移的重要转变,即迁移整个模型到新任务上,而这本质上是使用大型预训练语言模型作为可重用的语言理解特征提取器的方法。
这在当时也被称为「NLP 的 ImageNet 时刻」,与此同时,2019 年基于这一趋势的相关研究工作也在持续开展。
BERT 能够明显地让 NLP 任务轻易地实现迁移学习,同时在此过程中能够以最小化适应的方式在 11 个句子级和词级的 NLP 任务上,产生当前最好的结果。
从实用性的角度来看,这固然是令人兴奋的,但更有趣的是,BERT 和相关模型可以促进我们对于如何将语言表示为计算机能够理解的语言,以及哪种表示方法能让我们的模型更好地解决这些具有挑战的语言问题有基本的理解。
新出现的范例是:既然可以重新使用 BERT 对语言扎实掌握的基础,模型为什么还要不断针对每一个新的 NLP 任务从头开始学习语言的语法和语义呢?
随着这一核心概念与简单的微调步骤和相应的开源代码叒叒出现出现时,就从另一方面代表着 BERT 已迅速地传播开来了:翻译的语句要能体现出“很快传播”的意味:初发布于 2018 年底的 BERT ,2019 年就已经变成了非常流行的研究工具。
实际上直到我试图编撰一份去年发表的与 BERT 有关的论文清单时,我才意识到它到底有多受欢迎。我收集了 169 篇与 BERT 相关的论文,并手动将它们标记为几个不同的研究类别(例如:构建特定领域的 BERT 版本、理解 BERT 的内部机制、构建多语言BERT 等)。
下面是所有这些论文的分布情况:
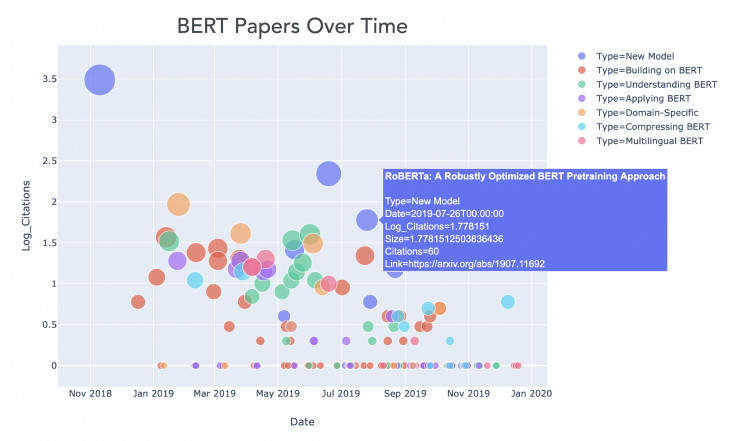
如图为在 2018 年 11 月至 2019 年 12 月间发表的与 BERT 相关的论文集合。y 轴代表的是对引文数目的对数统计(由 Google Scholar统计),它的下限为 0。这些文章中的大多数是通过在 arXiv 论文的标题中搜索关键词 BERT 找到的。
这种信息通常具有更好的交互性,因此这里我给出了它的 GIF 图。如果感兴趣的话,你也可以打开以 Jupyter 笔记本形式记录的原代码,可以自行调整图中的参数,相关链接如下:
上述实验使用的原始数据如下:
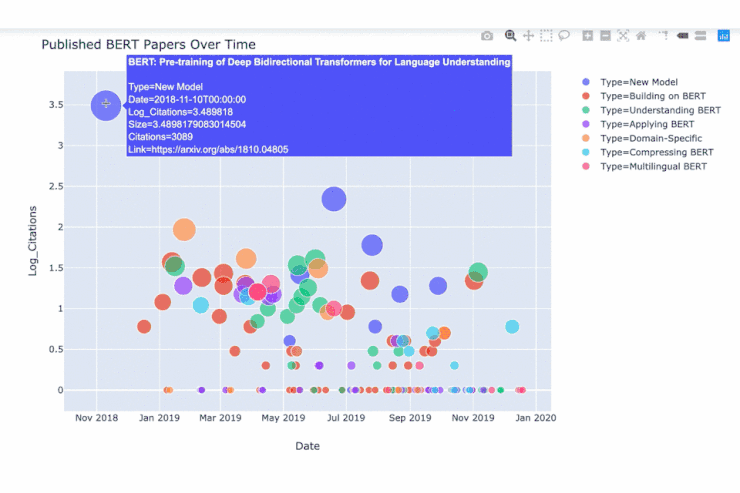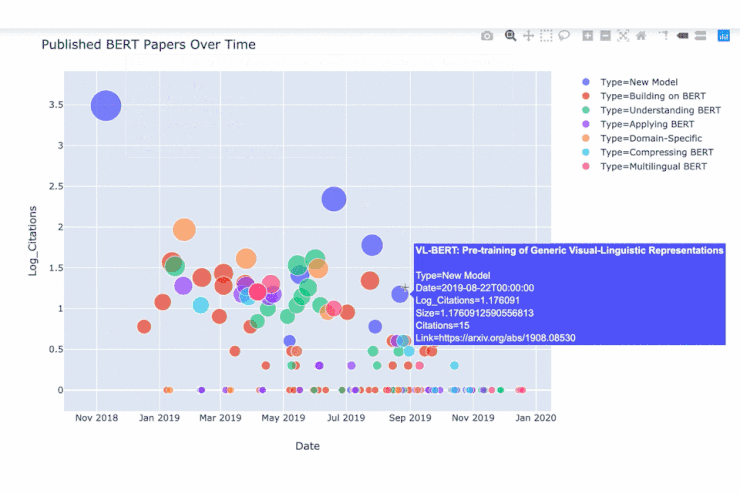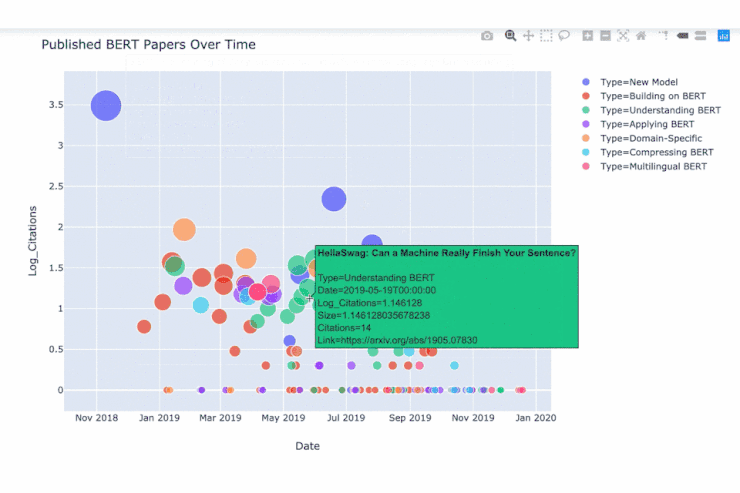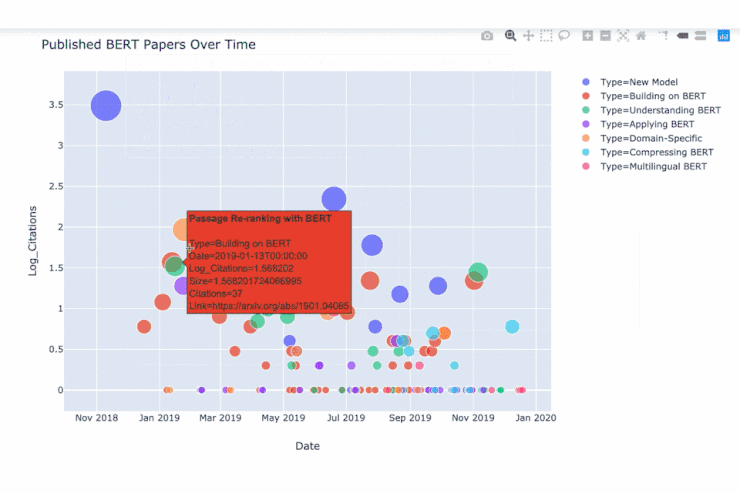
如图为在各篇 BERT 论文上移动鼠标时出现的数据。
现在已经有很多关于 BERT 的论文发表。从上图我们大家可以发现以下几点:
- 一个有趣的现象是,从 2018 年 11 月份发表 BERT 的原始论文的时间与大概 2019 年 1 月份开始出现一大波相关论文的时间之间的间隔,相当短。
- BERT (相关)论文最初的发表浪潮往往集中在一些核心的 BERT 模型的即时扩展和应用上(比如:图中红色、紫色和橙色部分),例如使 BERT 适用于推荐系统,情感分析,文本摘要和文档检索。
- 然后从 4 月开始,一系列探讨 BERT 内部机制的论文(图中绿色部分)相继发布,例如了解 BERT 如何通过建模进行语言的分层,并分析注意力头之间的冗余现象。其中特别令人印象深刻的是一篇名为「利用 BERT 重新探索经典 NLP 的传播途径」的论文(相关论文链接为:https://arxiv.org/abs/1905.05950)。该论文作者发现了BERT 的内部计算可以反映传统 NLP 的工作流程,即词性标记、依赖项分析、实体标记等。
- 然后在 9 月份左右,又发布了一系列有关压缩 BERT 模型尺寸的论文(如图青色部分),例如DistilBERT,ALBERT 和 TinyBERT 等论文。其中,来自 HuggingFace 的 DistilBERT 模型是 BERT 的压缩版本,其参数只有先前的一半(从 1.1 亿降至 6600 万),但在对重要 NLP 任务的实现上却达到了之前性能的 95%(具体请参阅 GLUE 基准; https://gluebenchmark.com/)。原始的 BERT 模型并不轻巧,这在计算资源不足的地方(如移动手机)是一个问题。
请注意这份 BERT 论文清单很可能是不完整的。如果与 BERT 相关论文的实际数量是本人所整理的两倍,我不会感到惊讶。在这里做一个粗略的数量估计,目前引用过原始 BERT 论文的数量已经超过了 3100。
如果你对其中一些模型的名称感到好奇,这些名称其实就是 NLP 的研究人员对《芝麻街》中的人物着迷的体现。我们大家可以将这一切归咎于(开先例以《芝麻街》人物命名)的论文 ELMo,论文相关链接如下:
这使得后来的诸如 BERT 和 ERNIE 模型也开始以相关任务命名,变得不可避免。我非常热切地在等待一个 BIGBIRD 模型,那么我们不妨将其压缩版本称为 SMALLBIRD?
一、从 BERT 文献中得出的一些启发
浏览这些文献时,我发现了其中出现的一些常见概念:
- 开源机器学习模型的价值。作者免费提供了 BERT 模型和相关代码,并提供了一个简单、可重复使用的微调过程。这种开放性对于加快研究进展而言是至关重要的,并且我有理由怀疑如果作者不那么直爽的话,该模型是否会受到同样程度的欢迎。
- 严肃看待超参数调整问题,认识到它的重要性。RoBERTa 的论文中,提出了一种更具原理化的优化设计(如更改训练任务)和更加范化的超参数调整方法来训练 BERT,这在学术界引起了轰动。这种不断更新的训练制度,再加上它只对模型使用更多数据进行更长时间的训练,就再次将各种 NLP 基准性能的纪录提升到了新的高度。
- 关于模型大小的想法。最初,BERT 作者发现了一个很吸引他的现象:即使在非常小的数据集上,仅通过简单地增加模型大小也可以极大地提高模型的性能。这也许在某种意义上意味着,你「需要」数亿个参数来表示人类的语言。2019 年的其他几篇论文中指出,仅通过扩大 NLP 的模型规模即可带来模型的改进(例如众所周知的 OpenAI 中的 GPT-2 模型)。当然,这里还有一些新的技巧可以用于训练大到荒谬的 NLP 模型(例如 NVIDIA 的拥有 80 亿参数的庞然大物 MegatronLM)。但是,也有证据表明,随着模型尺寸的增加,模型的效果会递减,这与计算机视觉研究人员在添加到一定多数量的卷积层时会遇到壁垒的情况相似。关于模型压缩和参数效率论文的成功发表,表明可以在给定大小的模型中获得更多的性能。
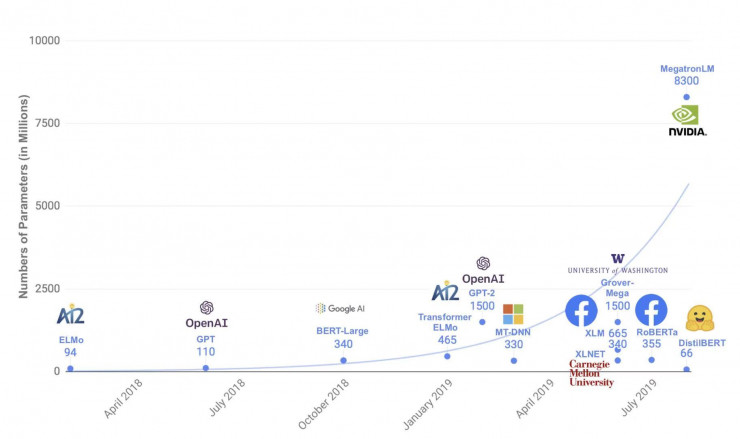
如图,我们的 NLP 模型慢慢的变大。摘自 DistilBERT 论文。
二、BERT 到底是什么?
让我们返回到前面,来讨论一下 BERT 到底是什么。
BERT(来自 Transformer 的双向编码器表示),是 Google 研究人员构建的一个预训练语言模型(LM)。这个语言模型是基于激励模型学习一个对语言深层理解的任务上训练的;LM 的一个常见的训练任务是预测下一个单词(比如:「猫坐在__上面」)。
BERT 基于相对较新的神经网络结构 Transformer,后者使用一种称为自注意力的机制来捕获单词间的关系。在 Transformer 中没有卷积(如 CNN)或递归(如 RNN)操作,注意力是你唯一需要的。已有一些已经出版的优秀教程(http://www.peterbloem.nl/blog/transformers)对此进行了介绍,所以在这里就不再做详细介绍,如下为相关概念的简短介绍:
- 自注意力机制是一种序列到序列的操作,它通过将每个词的内容融合到它的表示中的方式来更新输入标记的嵌入。这允许它同时对所有输入的字之间的关系建模,这一点与 RNN 不一样,RNN 中的输入标记是按顺序来读取和处理的。自注意力使用点积计算词向量之间的相似性,计算所得的注意力权重通常被视为注意力权重矩阵。
- 注意力权重捕捉单词之间关系的强度,我们允许模型通过使用多个注意力头来学习不一样的关系。每一个注意力头通常捕捉单词之间的一种特殊关系(带有一些冗余)。这些关系中的一部分是可以直观地解释的(比如主客体关系,或者跟踪相邻的词),而有些是相当难以理解的。你可以把注意力头集中看作是卷积网络中的滤波器,每个滤波器从数据中提取一种特定类型的特征,这些提取出来的特征将最大限度地帮助神经网络其他部分做出更好的预测。
- 这种自注意机制是 Transformer 的核心操作,但只是将其置于上下文中:Transformer 最初是为机器翻译而开发的,并且它们具有编码-解码器结构。可以将 Transformer 编码器和解码器的构造看作 Transformer 模块,其通常由自注意力层、一定量的归一化和标准前馈层组成。每个模块对输入向量执行此序列操作,并将输出传递给下一个模块。在 Transformer 中,它的深度是指 Transformer 中模块的数量。
BERT 模型通过使用上述 Transformer 设置,在 2 个无监督语言模型上进行训练。关于 BERT 训练,最重要的是它不依赖于标记数据,也就是说它能够正常的使用任何文本语料库,而不需要任何特殊标记的数据集。BERT 论文的模型就是使用维基百科和一本书的语料库进行训练的。与其他「普通」的语言模型相比,BERT 使用的数据是廉价的,这边是它所具备的一大优势。
三、BERT 是怎么样做训练的?
但是,BERT 是在什么任务上进行训练,能够激励它对语言的学习有这样良好及普遍有效的理解呢?未来的工作中也许可以调整学习策略,但原论文就使用了下面两个任务:
- 掩膜语言模型(MLM)任务。这项任务鼓励模型同时以单词级别和句子级别学习语言的良好表示。简单地说,一个句子中 15% 的单词是随机选择并用标记隐藏(或「掩蔽」)。该模型的工作原理是利用前后的单词预测这些隐藏的部分,因此,我们试图从损坏的输入重新建立起完整的文本,左边和右边的内容都被用来做预测。这允许我们搭建考虑到所有文本的单词表示。与 ELMo(一种基于 RNN 的语言模型,用于生成由上下文感知的单词嵌入)等方法不同,BERT 同时学习它的双向表示,而 ELMo 是由两个不同的语言模型分别独立地对从左到右和从右到左的语言表示进行学习,然后连接。我们大家可以说 ELMo 是一个「浅双向」模型,而 BERT 是一个「深双向」模型。
- 下一个句子的预测(NSP)任务。如果我们的模型被用作语言理解的基础,那么了解句子间的连贯性将有助于它实现目标。为鼓励模型学习句子间的关系,我们添加了下一句预测任务,在该任务中,模型必须预测一对句子是否相关,即一个句子是否可能继续连接着另一个句子。句子中的正训练对是语料库中真实相邻的句子,负训练对是从语料库中随机抽取的两句话。这不是一个完美的系统,因为随机抽样的一对句子实际上可能是相联系的,但这样对于任务的需要来讲已经足够好了。
上述模型必须同时学会两项任务,因为它实际的训练损失是两项任务损失的总和(即 MLM 和 NSP 可能性平均值的总和)。
如果你发现使用掩蔽的方法有点问题:那么你其实是对的。由于一个片段中随机有 15% 的单词被遮蔽,因此可能会出现多个。确实是这样,但是 BERT 将这些被遮蔽的单词彼此间看作独立,这是存在限制的,因为它们实际上很容易形成相互依赖的关系。这也是在 XLNet 论文(https://arxiv.org/abs/1906.08237)中提到的一点,有些人认为它是 BERT 的继承。
四、微调 BERT
一旦训练好的基础的 BERT 模型,后续通常需要经过两个步骤来对其进行微调:首先在无标签数据上继续进行无监督训练,然后通过添加一个额外的层并在新目标上训练,从而学习实际的任务(这里无需使用过多的标记数据)。
该方法最初源于谷歌研究者 Dai&Le 于 2015 年发布的 LSTM LM 论文,论文相关链接为:
BERT 微调实际上会更新模型中所有参数,而不仅针对新任务中特定层的参数,因此这种方法不同于将传输层参数完全冻结的技术。
实际中,使用 BERT 进行迁移学习,通常只有经过训练的编码器栈才会被重新使用——首先将模型的解码器切掉一半,然后将编码器 Transformer 模块用作特征提取器。因此,我们不关心 Transformer 的解码器对它最初训练的语言任务做出的预测,我们只关心模型内部表示输入文本的方式。
BERT 微调可能需要几分钟到几小时,这取决于任务、数据大小和 TPU/GPU 资源。如果你有兴趣尝试 BERT 微调,你可以在 Google Colab 上使用这个现成的代码,它提供对 TPU 的免费访问。相关代码如下:
五、BERT 出现之前的一些方法?
BERT 原论文写得很好,我建议各位读者再温习下,原论文链接为:https://arxiv.org/abs/1810.04805。我将论文中用到的此前语言模型预训练和微调常用的一些主要方法总结如下:
- 无监督的基于特征的方法(如 ELMo),该方法使用预训练表示作为输入特征,但使用针对特定任务的架构(比如:它们为每个新任务更改模型结构)。事实上,所有研究者最喜欢的单词嵌入方式(从 word2vec、GLoVe 到 FastText)、句子嵌入和段落嵌入都属于这一类。ELMo 还提供单词嵌入,但以上下文敏感的方式,标记的嵌入或者表示是从左到右和从右到左的语言模型隐藏状态向量的连接。
- 无监督的微调方法(如 OpenAI 的 GPT 模型),它对有监督的下游任务的所有预训练参数进行微调,并且只通过引入一些针对特定任务的参数,来最小程度地改变模型结构。预训练是在未标记的文本上进行的,学习任务通常是从左到右的语言模型或文本压缩(就像自动编码一样,它将文本压缩成矢量形式,然后从矢量重建文本)。然而,这些方法使得对上下文建模的能力受到了限制,因为它们对给定单词的模型通常是单向、从左到右的,它没有能力将所有后来的单词合并到其表示中。
- 从有监督的数据进行迁移学习。此外,还开展了一些工作来迁移从具有大量训练数据的监督任务中学习到的知识,例如使用机器翻译模型参数来对不同的语言问题的权重初始化。
六、问题以及需要仔细考虑的事情
计算机视觉领域,何凯明曾有一项工作《Rethinking ImageNet Pre-training》表明,预训练和微调主要有助于加快模型的收敛速度。这一思考和观点,是否也同样适用于 NLP 领域的工作呢?
- 何凯明论文链接地址:https://arxiv.org/abs/1811.08883
七、结论
我希望这篇文章对 BERT 所引发的研究热潮提供了一个合理的回顾视角,并展示了这个模型在 NLP 研究领域中是如何变得如此热门和强大。
目前这一领域的进展迅速,我们现在从最先进的模型中看到的结果,即便在仅仅五年前也是难以置信的)例如,在问答任务中表现出来的超越人类的性能。
NLP 领域最新发展进程中的两个主要趋势是迁移学习和 Transformer 的兴起,我非常期待看到这两个研究方向在 2020 年的发展。
Via https://towardsdatascience.com/2019-the-year-of-bert-354e8106f7ba
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!