数据分布偏移(data distribution shift)是可信人工智能系统热衷于考虑的一个话题,每年关于它的相关研究数不胜数。然而,仅关注分布偏移就足够了吗?
近期,纽约大学AI Now研究所的技术研究员Deborah Raji在UC伯克利助理教授Benjamin Recht的个人博客argmin上发表了对这一话题的看法。
她对于学界过度关注分布偏移感到担忧,认为更应该考虑统计上一个相关概念,即外部有效性(external vadality)。

数据偏移一直在可信人工智能上的一项“杀手锏”。例如,由美国史诗系统公司研发、被密歇根大学医院广泛应用的败血症识别模型在2020年4月由于频繁出现虚假报警,而被紧急叫停。据分析,这是因为新冠大流行导致的人口地理学特征发生了变化才使得模型出现偏差。
这是数据分布偏移的一个例子:当测试集的数据与训练集的数据分布发生变化时候,模型无法有效迁移到新的应用场景下导致出错。
这和不断变化的本质相关:真实世界的数据往往是动态的、变化的、不确定的,例如软件部署变化,人口迁移,行为变化,语言演变等,如果模型不将这些予以考虑,就会出现系统性偏差。
Benjamin Recht发表过这样一个另一惊讶的研究,他们重新按照ImageNet的数据收集方式收集了一批新的测试集,用原有的模型对新测试集进行准确性测试,发现了如下的结果:
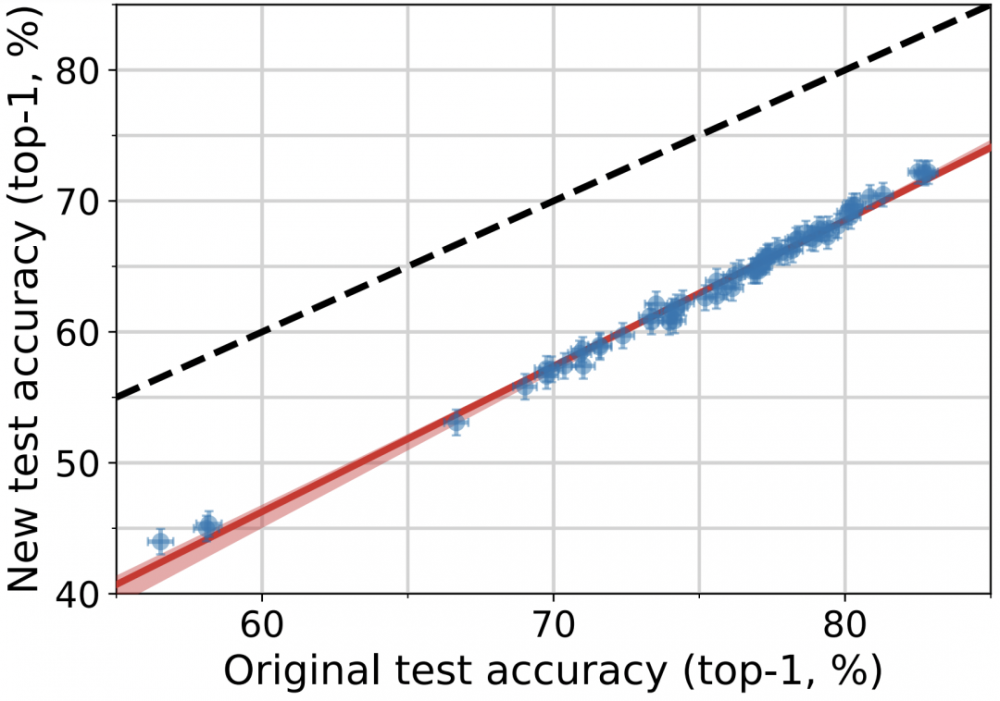
其中,横轴代表在原始数据测试集的测试性能,纵轴代表新数据集上的测试性能,蓝色的每个点代表一个模型的结果,红色的线则是对它们的线性拟合,黑色的虚线y=x代表理论上测试结果应该具有的表现。
可以看出,尽管二者之间仍然存在线性相关,即在原数据集上表现好的,在新的数据集也表现得很好,反之亦然;然而,它们之间仍相差将近15%的差距,这就是由于数据分布偏差所导致的。这里的偏差可能来自不同的标注者偏好,不同的数据收集过程等等。
Deborah Raji承认研究这种现象的重要性,但她认为ML的研究者们太过于执着于关注分布偏移这一话题了,以至于很多情况下将模型的任何失误都归因于了分布偏移,而她认为这是不合适的。
首先,她认为“分布偏移”这一问题有时候太过具体,有时候又不够具体。任何数据上的变化都可以认为是一种“分布偏移”,例如数据特征本身的变化、数据标签的变化以及二者都发生的变化。
另一方面,这一术语又太宽泛模糊了。“数据分布”这个概念自身就需要假设数据来自一个假象的“真实”分布中,而现实可以观察到的数据则是从这一整体分布中独立同分布的采样数据。然而这个分布是什么呢?没人知道——真实数据混乱、无序、不可预知。
数据分布偏移了,可是哪些部分发生了变化,为什么它们发生,这些都无从得知。
Deborah Raji进而警告道,对于这一术语的痴迷会如何限制ML社区的发展。一个表现是,现在的社区热衷于开发检测数据分布偏移的基准测试,以此来声称测试偏移的程度。然而这些数据是静态的、理想的,无法适应真实世界更加复杂的数据。
有些研究已经开始得出结论:过度强调数据分布偏移已经使得ML实践者和政策制定者更专注于回顾性研究(retrospective studies),而非前瞻性研究(prospective studies)。前者针对于静态收集的历史性数据而言,后者则更加着重于系统的上下文背景。
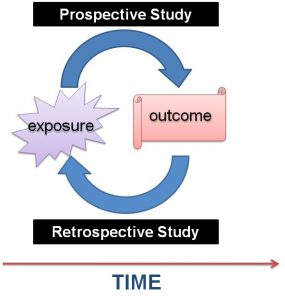
回顾性研究与前瞻性研究
为此,Deborah Raji希望研究可以更加转向“有效性”(validity)这一概念。有效性是统计中测度论(measurement theory)中的重要概念,用以衡量系统的可信赖性。有效性又包含内部有效性(internal validity)和构建有效性(construct validity)。当讨论泛化性的时候,我们更关注于外部有效性(external validity)。
外部有效性衡量模型如何泛化到其它场景、设定。这些测试的设定往往不是实验原有的环境,并且考虑到不仅仅是数据方面的变化。
Deborah Raji以一篇文章为例,这篇发表在JAMA的,名为“在住院患者中广泛使用的败血症预测模型的外部有效性分析”对于开头中的那个例子中的模型做了更加详尽的“外部有效性”分析。

网址:https://jamanetwork.com/journals/jamainternalmedicine/article-abstract/2781307
首先这篇文章描述了一项关于 2018 年 12 月至 2019 年 10 月期间(尤其是在大流行开始之前)使用败血症模型的回顾性研究。他们检查了接受38,455 次住院治疗的27,697名患者,发现Epic模型预测败血症发病的曲线下面积为 0.63,而“这比其开发人员报告的性能要差得多”。
此外,该工具“未识别出 1,709 名败血症患者(67%),因此造成了很大的虚假报警。”
这些研究人员正确地将这些问题描述为“外部有效性”问题,并详细研究了它们,这远远超出了“临床医生和数据集偏移”——一个静态的偏移数据集中描述的数据分布偏移。
对于Epic 系统的评估是基于 2013 年至 2015 年 3 个美国卫生系统的数据,这与密歇根大学 2018-2019 年的患者记录数据不同。但该评估不仅仅考虑数据问题,还评估了医生与模型交互的变化以及这些变化如何影响结果,以及其他与数据几乎没有关系的外部有效性因素——这远超过了数据分布偏移。
即使在讨论实质性的数据更改时,研究者们也会试图具体描述它是什么,并具体分析在他们医院部署时发生的差异。

作者Deborah Raji是尼日利亚裔加拿大计算机科学家和活动家,她致力于研究算法偏见、人工智能问责制和算法审计。她曾与 Google 的Ethical AI 团队合作,并曾在纽约大学AI和AI Now研究所的合作伙伴关系中担任研究员,致力于研究如何在机器学习工程实践中考虑道德因素,曾于AI公正性研究的Timnit Gebru做过同事,也曾获得过该领域多个奖项。
Deborah Raji与Ben Recht已经在这个外部有效性这一话题上已经展开了很多深入的讨论,后续关于这一问题的探讨也会陆续放在arg min的博客上,感兴趣的读者可以关注查看~
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!