2023年的AI大模型,已经从Q1火到了Q2。
国内,从大厂到新创,纷纷下场试水,几个月过去,已经有了不少大模型产品“交卷”受评,颇有“乱花渐欲迷人眼”的架势。
看客只识AI大模型百花齐放,但除了一场热闹以外,却也开始有人问出了这个问题:
“AI大模型这么厉害,但它有啥用呢?”
诚然,市场上不少公布的大模型,还并未开发到完全程度——甚至距离“可用”、“好用”还差着一些距离。
在一些AI大模型产品,仍旧在“胡说八道”、场景落地难、语义理解能力弱等问题中徘徊时,OpenAI 首先看到了落地的痛点,和微软合作推出 Copilot,主打在办公领域提升工作效率,打响了大模型向生产力进军的发令枪。
在人们的想象中,AI 应该可以帮助处理机械、重复的日常工作,提供独特的分析视点、创作灵感,在特定的领域——比如教育、医疗、法律——给出独特的建议和帮助,让工作和生活更轻松、便捷,让每个人都能够享受更贴心细致的服务。
而什么样的AI大模型,才能真正地帮助使用者“干活”?让日常办公、生产的效率得到更大提升?什么样的大模型,才真正算得上生产力工具?要满足生产力工具的要求,大模型需要有哪些秘密武器?
对于业界来说,这些问题如果得不到解答,那么或早或晚,都会遇上市场的瓶颈;而越早能够为市场提供效率提升的大模型产品,也就能够越早地占领先机。
一、理解&记忆:大模型生产力的分水岭
记忆和理解能力,对于当下如同雨后春笋的大模型产品来说,说得上是最硬核的实力比拼。
模型的理解能力,根植于对自然语言的处理能力,能够清晰地辨别语义,尤其是一些根植于本地语言语境中的俗语、幽默,对于理解用户想要什么,进而完成文本生成和创作,至关重要。
而模型的记忆能力——也就是多轮对话能力——越强,使用者就能更详细地对需求进行描述,进而利用 AI 完成更加复杂的工作任务;
大模型比拼中最“硬”的两个科目,也是大模型提供生产力的关键保证。不仅如此,不如说,要大模型能够真正帮人“干活”,记忆和理解能力,都要满足更高的要求。
但无论是“理解”还是“记忆”,都是大模型在当下的能力提升的攻关难点。一方面是市场的巨大痛点,一方面是技术上难攻不落的“高墙”,这对矛盾不解决,AI 的生产力就始终面临着一个艰难的瓶颈。
首先,要解决 AI 语义理解能力差的问题,昆仑万维和奇点智源的 AI 科学家们想到了一种另辟蹊径的方法——蒙特卡洛树搜索算法。
蒙特卡洛树搜索算法,简单来说一种基于随机模拟的强化学习算法。对 AI 不甚了解的人可能并不知道它的名字,但它却是AlphaGo能打败李世石、柯洁等一众围棋高手的秘密武器。而蒙特卡洛树搜索的核心,就是通过一个树状结构,在每个节点进行随机搜索,并找到最优决策的方式。
在昆仑万维和奇点智源联合发布的AI大语言模型——“天工”中,蒙特卡洛树搜索可以让AI“三思而后行”——AI 会基于过去用户的对话记录以及当前用户的输入生成候选大量回复,并结合NLP技术,选取最佳的回复方案反馈给用户。
通过把蒙特卡洛树搜索算法,和自然语言处理相结合,让Decoder的安全性和准确性获得了极大的增强,也让天工在相对复杂的任务和场景中,能够快速且准确地响应指令,输出高质量回答。
为了测试天工的语义理解能力,小编向天工提问:“什么是蒙特卡洛树搜索算法?”天工的回答还比较清楚,令人满意:

把蒙特卡洛树搜索应用到 AI 对话机器人中,另一个优势,是AI能够理解如何在对话中转换话题,并提出问题,引导用户完善自己的Prompt,以得到更好的回复结果。
比如,小编故意问出了一个十分宽泛、难以回答的问题。天工则并没有落入这个“陷阱”,通过主动提问,缩小问题的范围:

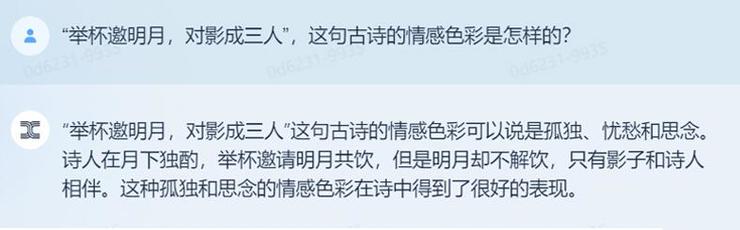
而为了测试天工的中文语义理解能力,小编向天工询问了一句古诗的情感色彩,不得不说,天工把握得相当不错:
在不错的语义理解能力之上,天工的“文采”,也出人意料。它给出的结果稍作修饰,就能变成一篇不错的短文:

在文本的翻译中,也能看出天工对中英双语的娴熟运用,在用英文描绘诗词时,甚至也能品到中文的“原汁原味”:

而提到记忆能力,天工更是出人意表,能胜任超过20轮以上的对话,支持万字以上的超长文本。单就这一点,足以让不少同类产品望尘莫及。
比如下面的对话,天工就在连续对话上小试牛刀,还能够理解“沙特球王”的足球梗,

在超强连续对话能力的背后,是天工的“财大气粗”。背靠中国最大的GPU集群之一,天工有超级丰厚的资源,保证运行和相应的速度,同时也让用户资料安全与使用体验更加稳定、可靠。
理解能力和记忆能力,足称得上是大模型产品在生产力上的分水岭——在深度理解用户需求的基础上,能够实时地完成连续对话,能越过这道坎,AI 才能开始为用户提供生产力的保证。
二、场景优化&模型鲁棒性:好用=可用+可靠
尝试过用 AI 写稿的记者,尤其是某些垂直领域的记者,也大多心中都有过隐隐的担忧——如果 AI 在某些关键信息点“一本正经地胡说八道”,而自己没有发现,最后就会造成严重的事故。
诚然,大模型的“幻觉”问题,可以通过知识图谱,以及上文提到的蒙特卡洛树搜索算法,进行一定程度上的抑制;而到了专业领域,场景优化做不好、训练数据质量低,AI 再巧,面对的也是无米之炊。
用 AI 用得不放心,还不如自己亲自上阵——不少人都是因此,对 AI 敬而远之。而没有人用,就无法获得足量数据来继续训练、修正模型,进而形成了一种恶性循环。
尽管幻觉问题的解决并非一朝一夕,但当下的AI 大模型要做到“好用”,首先得“可用”和“可靠”。在工作、教育等垂直场景落地,大模型得有一些“绝活”。
首先是数据需要“保质保量”,一方面数据要足量,支撑模型训练的要求;另一方面,数据的质量也必须够高,否则训练出来的模型,反而容易被不良数据“带跑偏”,甚至让训练起到反效果。
其次,是模型的鲁棒性——即,模型在发生异常情况,或面对不良数据时,自身的“抵抗力”。鲁棒性越强的模型,自身的稳定性和有效性就越不容易受到内外的不良影响,也就自然更加“可靠”,进而能在更广泛的场景中,为使用者提供生产力提升。
而为了能够真正帮上用户“干活”,天工在这两点上也下足了功夫。
首先,昆仑万维和奇点智源,从数十万亿的数据中,通过层层清洗和筛选,得到了三万亿的高质量单词数据,供给天工完成训练。
其次,昆仑万维在2020年开始,就在AI领域开始布局,以“天工巧绘”、“天工乐府”、“天工妙笔”、“天工智码”四个开源AIGC模型为旗帜,在自家的开源社区汇集了百位开源社区AI科学家,积累了深厚的开源社区力量。
同时,天工在大规模与训练的基础上,针对不同的情况,进行了场景化的微调,让天工能够应对更多的场景,并且提供高效、个性化的帮助。
无论从事法律工作,还是医健、财务等,天工都能在专业角度提供帮助:

不仅如此,面对教育场景,天工也能轻松应对,无论是数学、物理,还是历史、政治,天工的辅导也堪称专业,帮助家长省区了不少时间:

除此之外,AI 大模型产品常常落后于时代,数据库无法和当下的最新信息接轨,也是常常被外界诟病的原因之一:不能提供最新的知识,AI 又该怎么为使用者解决日新月异出现的问题呢?
由此,AI 对话的实时性,也自然而然地成为了评判大模型能否提供生产力的重要标准。
在这个维度,天工依靠大模型强大的智能涌现能力,与实时知识库打通后,达到了能够实时迭代知识的效果,让用户能够实时通过 AI 获得最新的信息,不再“落后于时代”:

三、千亿模型:只有“一个”或许不不够
谈到大模型的能力,绕不开的一个概念,就是“涌现”。
简单来说,“涌现”,指的是预训练 AI 在训练参数达到一定量级时, 表现将突然呈现指数级的上升,甚至获得没有被专门训练过的能力。
在业界的普遍认识中,500-600亿规模的训练参数,是预训练大模型产生涌现现象的门槛。而参数规模越大,一般认为,模型的能力也就越强。
于是,千亿参数,目前已经成了大模型的“标配”,时下不少大模型产品,都把自己叫做“千亿模型”,以参数量见模型实力。
但在当下,却也有人问出了一个问题:
要让大模型提供生产力,千亿模型,一个就够了?
对于昆仑万维和奇点智源来说,他们理想中 AI 大模型的底层架构,是由“千亿预训练基座模型”,和“千亿RLHF模型”——两个千亿模型搭起来的。
前者,千亿预训练基座模型,主要负责各种自然语言处理任务,可以实现语言生成、文本分类、机器翻译等功能。
后者,千亿RLHF(人类反馈深度学习)模型,则会通过人类对 AI 输出结果的反馈,来改善强化学习的性能。
如果把预训练基座模型,比作一个读书破万卷、天资聪颖的“学神”;那么RLHF模型,则像是一个在刷题中不断试错、进步的“学霸”。
在今天,看到了 ChatGPT 在 AI 领域的突飞猛进,RLHF 也正逐渐成为了不少大模型的标配。而天工使用了预训练基座模型+RLHF的模型体系,让两个模型相互映照配合,也有深意。
一边,是双千亿模型的结构,能让最终的模型性能获得更大的提升,也能让模型的可解释性与学习能力、任务支持大大增强。
一边,是训练时间和资源消耗的降低——预训练模型所学习的通用特征,可以作为RLHF模型的初始参数,让训练这个最“烧钱”的项目,能够多快好省地完成。
在上文中提到的,模型对于异常情况和不良数据的鲁棒性,很大程度上,也是通过两个千亿模型“双剑合璧”,进而实现的。
再高的大厦,功夫最重也是在基础。双千亿模型,是天工能够成为生产力工具,最重要的顶层设计之一。昆仑万维和奇点智源,在规划技术路径之初,就已经看到了当下大模型产品的设计局限,与双千亿模型可行的技术路径,并以此为基础,将整个天工搭建于其上。
如同一棵树木,拥有了健康、坚固的根系,才能长成粗壮的树干、茂密的枝桠,丰饶的果实才能生长出来,最终成为人们的收获。
结语:
过去的几年里,科技圈已经见过了太多的风口,来了又去,最终雁过无痕。
归根结底,在风口正盛的时候,这些人们对未来的想象,并没有能够化为实际的生产力,推动业界乃至整个社会向前进步,最终当热潮涌过,大概避免不了沉寂的命运。
于是,在这一波生成式 AI 的风口,也有人问:这次会不会和之前一样,潮起潮退,沙滩上只留下一批一批的“裸泳者”?
如果 2023 年的 AI 创业者们,不甘于止步于空谈,那他们就应该知道:大模型不应该只是一个美好却空洞的花瓶。AI 应该成为下一个十年的内燃机和交流电,推动下一次产业革命。
在这个过程中,天工想要做的,一直是一个生产力工具,一个“真正能帮你干活的 AI”。
也正是基于此,天工从中国最大GPU集群支撑的超强算力出发,打造了双千亿模型体系,并在AI开源社区的共同助力下,开创性地把蒙特卡洛树搜索算法,与NLP技术相结合,保证了AI 可以为使用者提供实打实的生产力赋能。
什么样的大模型,才能成为生产力?天工的模式,可以说为大模型赛道的其他竞逐者——无论是先发的,还是后来的——打了一个样。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!