作为一门高度抽象化和具有逻辑推理特性的研究,数学建模似乎离我们很遥远。
事实上,日常生活中运用到数学模型解决问题的事例俯拾皆是:打车系统里,算法会匹配距离乘客更近的司机、规划最快到达目的地的行程路线;购物平台上,算法会调配库存充足的出货仓、计算中途的运转站和物流配送车辆……
对大部分人来说,使用数学工具是件门槛极高的事情。但大模型的出现,改变了这一现状。在数学家陶哲轩的手中,细节到检索公式定理、翻译论文、整理文献,大到为论文生成图表、寻找灵感,ChatGPT 已经成为他科研的常用助手。
而研究之外,大模型对数学的影响还远不止于此。
晞德求索科技,一家专注于数学赋能的初创公司,团队基于大模型发布的自动数学建模工具 SeedModeler,就将大模型与求解器完成了融合打通。
如何让数学在具体生产环节中发挥作用?SeedModeler 给出的思考是,贯穿问题理解、数学建模到模型求解全流程,借助大模型,建立自然语言到计算机语言的跨领域对齐,降低使用求解器的门槛,从而提高数学建模的应用效率,让数学服务更多人。
一场「大模型+数学」的跨语言对话
长期以来,求解器的应用都面临着语言门槛的问题。
现实生活中,生产调度、供应链管理、排工排产、库存和运输优化等许多复杂的规划和决策问题都能使用求解器来解决。一个形象的比喻是,求解器类似于计算器的角色。企业采购一批物资,需要采买的材料可以在头脑中列出一份清单,但是怎么买价格更低、组合更优惠、用哪家的物流路线更快等等,实际需要考虑的要素呈几何倍数增加,这个时候使用求解器,可以辅助我们快速计算得到更精准、更科学的方案。
这个过程中涉及到五个具体步骤:首先,明确待解决的业务问题,定义优化问题三要素,用计算机语言来建立对应的数学规划模型,将该模型导入到求解器中求得最优解或可行解,最后参考解法进行决策。
其中,由于业务端往往给出的是自然语言的具体问题,导入求解器中,需要转换为特定的数学语言或计算机语言,这对没有建模能力的业务人员来说无疑是极大的挑战。
在探索将数学求解器商业化的过程中,晞德求索的团队也发现了这一痛点:大规模使用数学工具的主要门槛在于如何将场景问题提炼成数学模型。要使用求解器,就必须要额外付出成本去解决的数学门槛,许多需求都被拦在门外。
为此,作为一支由数学或计算机研发人员组成的团队,晞德求索基于一些模板和方向,开始了求解器低门槛推广路径的探索,但在一段时间以来,其表现却未能尽如人意。直至大模型出现,改变了这一困境。
大模型究其本质,是用自然语言处理在人类和机器之间,构建了一个可理解、相对清晰的逻辑描述和语义对齐,并以便捷易用的交互界面,让大众都能用起来。在此基础上,晞德求索从多年来在数学建模和求解领域所积累的经验、丰富的数据出发,将整套建模和求解器应用流程进行整合,提出了自动数学建模工具 SeedModeler。
常规的数学模型搭建离不开三个关键性要素,分别是定义决策变量、建立目标函数和确定约束条件。其中,
- 定义决策变量,指确定需要优化的变量。以供应链采购场景为例,需要考虑的变量就包括了每个供应商的采购数量、运输方式和每种原材料消耗数量等;
- 建立目标函数,指的是确定优化的目标,即希望在采购过程中最大化或最小化的指标。例如将目标函数设置为最小化总成本,包括采购成本、运输成本和库存成本等;
- 确定约束条件,指的是要确定问题的限制条件,以保障解决方案的可行性。比如供应商的供应量上限、交货时间等,都属于要纳入考量的要素。
具体到供应链场景下,假设某企业生产某产品需要不同原料,且该企业有不同的供应商,每家供应商的价格不同且每周可以供应的原材料数量有上限。采购人员需要根据供应商报价和生产需求,计算出一个成本最低的采购方案。
这个过程中,如果将采购问题转换为数学模型用求解器进行计算,企业不仅要求助额外的数学建模工程师、根据具体需求搭建模型,同时,即便是有建模经验的工程师,面对生产场景里的精细化问题,也往往需要一周甚至更多的时间建立模型和修改模型,企业所对应的人力成本和时间成本被拉高。
但有了 SeedModeler 之后,企业就无需再专门招聘建模工程师,面对具体的业务问题,采购人员只需用自然语言将问题描述输入 SeedModeler 中,即可得到由 AI 自动分析问题后给出的对应的数学模型,大大缩短了过去用户问题与求解器应用的距离,帮用户低成本跨越了求解器的使用门槛。
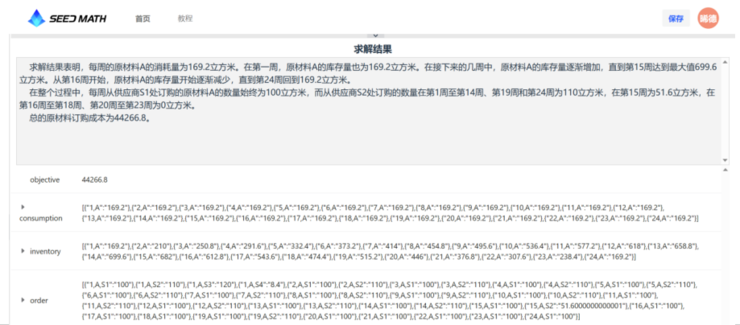 不仅如此,针对生产环节中的具体问题,SeedModeler 还会根据具体情况提出针对性建议,用户也可以根据自身需求,对数学模型进行修改。
不仅如此,针对生产环节中的具体问题,SeedModeler 还会根据具体情况提出针对性建议,用户也可以根据自身需求,对数学模型进行修改。
当采购人员确认了所有因素均已被纳入数学模型的考量后,即可生成代码,由 SeedModeler 提出相对应的数学模型代码,并生成测试数据。最后,采购人员点击求解,SeedModeler 就会调用求解器进行求解,并以自然语言和结构化数据给出对应的采购和生产方案。
从专业人员需要一周的建模周期,到非专业人员没有数学基础、仅需几分钟就能完成一个数学建模,SeedModeler 将以往传统的求解器应用问题,基于大模型的自然语言能力和交互能力,全面嵌入 AI 自动化数学建模的流程中,让模型来适应用户,降低数学建模和求解器的应用门槛,极大地提高了用户对数学生产工具的使用效率。
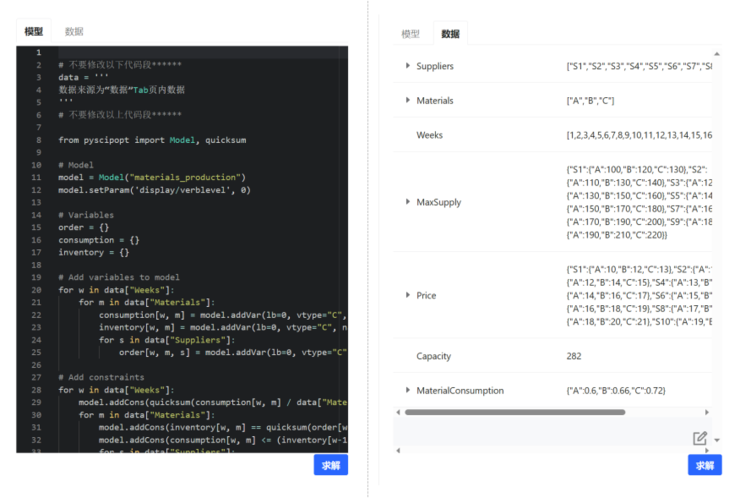
目前,晞德团队已将 SeedModeler 应用于日常的建模工作中,搭配晞德的多款求解器,打通了从问题到模型到答案的数学赋能产业的全流程。
将数学与大模型进行融合,在新的技术底层之上释放数学工具的生产力,这也为大模型应用创业公司提供了一个新的参考路径。
对话林锦坤
小编:目前市面上陆续发布了不少数学大模型,与其他产品相比,SeedModeler 的差异和优势分别是什么?
林锦坤:SeedModeler 不是另外一个数学大模型,而是大模型在自动建模领域的应用。
现实应用中的数学模型通常涉及大量复杂而相互关联的约束,与我们平时所做的应用题或数学题是不同的,这类问题通常需要调用专业的求解器才能解决。
过去推广求解器时我们发现,虽然求解器很好用,但要把它应用到实际问题中,前期有很长一段路要走,需要将对应的工作问题抽象描述为数学模型、再使用求解器。这一步通常需要投入很重的人力成本和时间成本,如果要普及求解器,就必须降低使用门槛,SeedModeler 正是为此而研发的。
据我们所知,目前市面上还没有针对这个应用领域而开发的大模型。
小编:SeedModeler 解决的是工作流中建模环节的效率,有其通用性、也需要考虑具体使用场景的行业性问题,它底层的技术原理是什么?
林锦坤:通常情况下,数学建模的难点在于处理问题中存在的复杂约束,并用正确的数学公式表达出来。对于不同的行业场景下的问题约束,在数学本质上的差异通常并不会特别大。
SeedModeler 基于晞德求索团队多年来在数学建模和求解领域所积累的经验、丰富的数据,以及大模型的自然语言理解能力和指令理解能力,将整套建模流程进行了整合。
小编:以具体场景为例,介绍一下 SeedModeler 是如何发挥作用的?
林锦坤:以供应链问题为例,假设某企业生产某产品需要不同原料,且该企业有不同的供应商,每家供应商的价格不同且每周可以供应的原材料数量有上限。同时,企业的需要保证一定的库存余量,以确保一段时间的生产能够正常进行。如果你是该企业的采购人员,你该如何根据供应商报价、企业生产计划、原材料库存计算出一个成本最低的采购方案。
用求解器可以很好地解决这个问题,但是,由于生产问题多以自然语言或流程图的形式呈现,使用求解器、避免不了将问题转化成为数学模型和求解代码,这对于非专业人员而言比较难。期间团队构思和探索了一些模板和方向,但效果都不是很好。直至大模型的出现,让我们觉得非常惊喜。
SeedModeler 通过整合大模型的能力,可以实现从自然语言问题到公式语言的转化,自动建模数学模型,并且生成相应的求解代码,一键求解得出最优的采购方案,从而极大程度地提高企业决策效率。
小编:训练 SeedModeler 需要哪些方面的数据?面对金融、医学等数据保密性高的垂直领域,数据样本问题如何解决?
林锦坤:SeedModeler 需要的数据主要来自于不同类型问题的数学模型,尤其是那些涉及复杂约束的数学模型。正如上面所提到的,在数学本质的层面,不同领域的问题建模差异通常不会特别大,因此对垂直领域来说,数据保密性高对于数学建模的影响并没有想象中的大。
例如,用户提出问题需要用到运筹优化的求解器,对应模型则是从运筹优化的方向进行建模,这当中与问题相关的领域数据、对建模影响并不大,关键是基于问题描述本身以及对应的数学模型如何生成。
当然,SeedModeler 还在优化和完善的过程中,对于某些特定领域下的特殊类型约束,SeedModeler 还需要再针对性地吸收这类问题的建模经验。随着这方面的积累增多,SeedModeler 的建模能力也会越来越强。
小编:关注到目前晞德求索的成员大部分深耕数学求解器领域多年,这样的人员组成对 SeedModeler 的研发有什么影响?
林锦坤:我们团队核心成员从事求解器多年研究,如何让更多人走近数学、让数学服务更多人是我们一直以来的追求和愿景。使用求解器的前提条件,是将问题准确地描述为合适的数学模型以及相应的求解代码,这个过程不仅需要专业的建模和求解知识,并且费时费力。
ChatGPT 出来后,其表现令我们十分惊喜,于是便思考将 ChatGPT 跟求解器相结合的可能性,基于多年来的建模和求解经验,用几个月时间迅速研发出了 SeedModeler。
小编:SeedModeler 的目标客户群体包括哪些行业?
林锦坤:需要使用数学建模的行业都能够从 SeedModeler 获益,包括生产调度、供应链管理、排工排产、库存和运输优化等。
目前,SeedModeler 还属于一个新研发的产品阶段,接下来会逐步对外开放。此前一直作为公司内部的建模工具,为公司提高所承接项目的建模效率。
小编:从产品角度来看, SeedModeler 的能力表现、跟模型在不同细分行业场景中应用的相关性大么?具体效果如何?
林锦坤:SeedModeler 属于大模型在细分行业场景中的应用,主要致力于降低数学的使用门槛,尤其是降低使用求解器来提高效益的门槛。其主要功能包括:将自然语言描述的问题转化成为数学模型,给出改善模型的专家建议,允许客户用自然语言修改数学模型,生成模型求解代码,使用求解器给出原问题的求解结果。
过去在涉及到复杂场景的问题时,可能需要两三个月、甚至更长时间才能完成数学建模和代码编写,在此基础上再进行求解器的调用,有了 SeedModeler 后,这一情况得到了改善。据内部测算,借助 SeedModeler 平台能力,只需几分钟时间即可完成一个数学建模,即使是面向更复杂的场景优化问题,用户也只需对模型进行简单的修改和再适配,极大地提高了决策效率。
小编:现阶段来看,行业/领域大模型被认为是大模型落地可行性最高的方向,您怎么看待这种观点?这是否也是晞德求索从数学 GPT 切入的原因之一?
林锦坤:从短期内的应用而言,我是支持这个观点的。
目前,通用大模型的最高性能是 OpenAI 的 GPT-4,其他各个大模型还在追赶过程中。但即使是 GPT-4,在许多垂直领域中的应用仍然存在许多瓶颈。因此,利用垂直领域的经验和数据积累,借助大模型的能力,是非常有希望能够做得很好的。这的确也是晞德求索借助大模型来完成自动建模的原因之一。
但另一方面,降低数学使用的门槛一直是晞德求索的初衷,实际上在大模型没有流行之前,晞德求索就已经在筹划自动建模的内容了,现在赶上了大模型成熟的时机,对我们而言是一个很好的机遇。
小编:SeedModeler 的大模型路线是什么样的?目前瞄准的是自动建模方向,是否意味着未来还会支持更多细分方向?
林锦坤:从接入大模型的技术路线上,晞德在考虑私有部署大模型的计划,以更好地打造产品。SeedModeler 之后的发展仍然会是降低数学使用门槛的方向,尤其是降低各类数学求解器的使用门槛。SeedModeler 将来会支持更多类型的数学模型,例如图论模型、一阶逻辑模型等。同时,针对大规模的问题求解,我们还计划让 SeedModeler 支持分阶段建模求解。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!