本土大模型时代早晚会到来是业界共识,但却没想到来的这么快!
近日,中国大模型火了,在全球知名大模型开源社区HuggingFace上百川智能的两款开源模型Baichuan7B、Baichuan13B受到了全球开发者们的热捧,Baichuan开源系列近一个月下载量超347万次,是月下载量最大的开源模型。
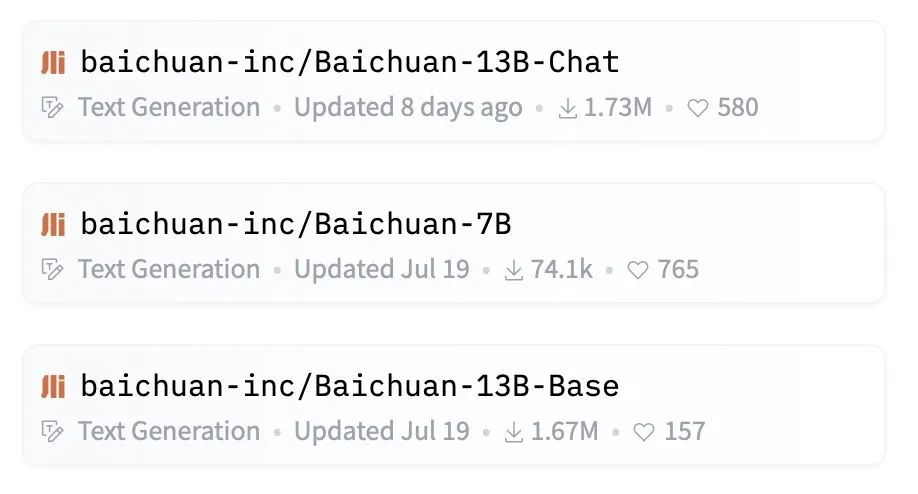
其中Baichuan-13B-Base在HuggingFace的下载量高达167万次,Baichuan-13B-Chat的下载量超过173万次,远超LLaMA/LLaMA-2-13b-hf的14.9万。
持续助力开源生态,百川智能再发两款开源大模型
百川智能并未因此而沾沾自喜,在以开源模型助力中国大模型生态发展愿景的驱使下,9月6日,百川智能召开主题为“百川汇海,开源共赢”的大模型发布会,会上宣布正式开源Baichuan 2系列大模型,包含 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化,并且均为免费可商用。
Baichuan 2下载地址:https://github.com/baichuan-inc/Baichuan2
一直备受瞩目的百川智能,自成立以来平均 28 天就能发布一款大模型。如果只是在速度上持续领先,或许可以理解为本就是一个“明星”创业公司的“分内之事”。但如果保持研发速度的同时,在质量上还完成了对LLaMA2的超越甚至是吊打,那必须值得称赞一番。
本次百川智能发布的 Baichuan-2 实现了对 LLaMA2的全面碾压,这意味着中国开源大模型进入到了本土时代。
全面超越LLaMA2,Baichuan-2杀疯了
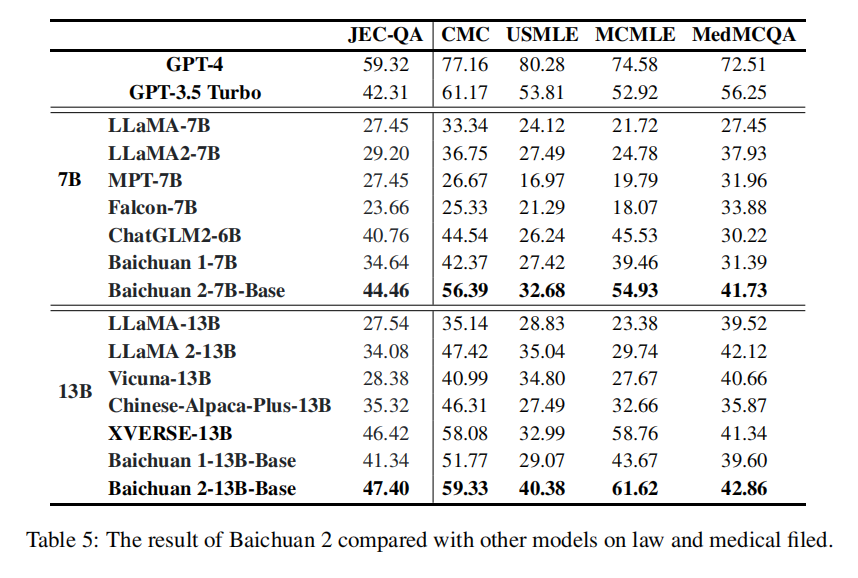
口说无凭,为评估模型的整体能力,Baichuan 2 系列大模型选择了包括MMLU、CMMLU、MedQA USMLE在内的8个基准,从总体性能、垂直领域、数学和编程、多语言、安全性以及中间检查点六个部分进行了整体的 LLM 评估。
结果显示 Baichuan 2 系列大模型在大多数评估任务中的表现大幅领先 LLaMA2,紧追 GPT。
相较于此前开源的Baichuan-13B-chat,Baichuan2-13B-Chat在安全、对话、逻辑推理,语义理解、代码等方面的能力有显著提升,其中安全提升29%,对话提升42%,语义理解提升50%,逻辑推理提升58%,代码提升70%。
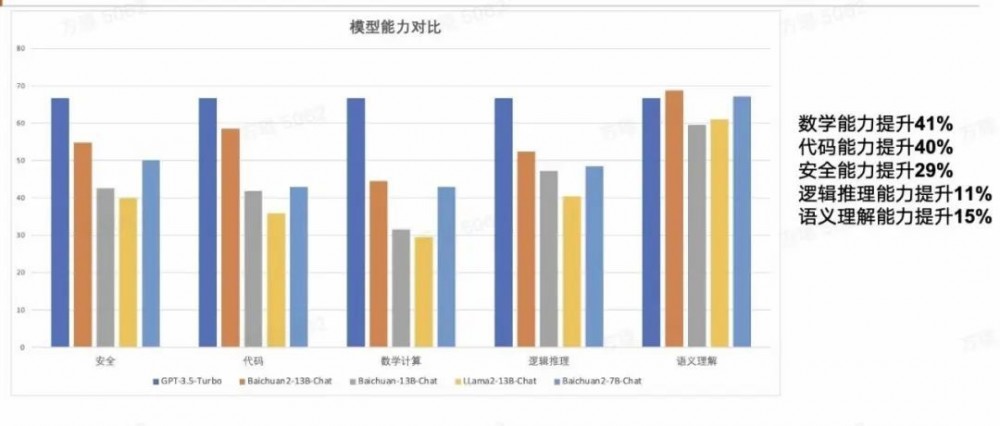
不仅如此,Baichuan2-7B 仅凭70 亿参数在英文基准上就已经能够与 LLaMA2 的 130 亿参数模型能力持平。这更从侧面证明了Baichuan2系列模型在同参数级别下吊打LLaMA2的真实性。
Baichuan2之所以如此强悍,是因为百川智能在研发过程中借鉴了很多搜索经验,对大量模型训练数据进行了多粒度内容质量打分,同时Baichuan2-7B和Baichuan2-13B训练时均使用了 2.6 亿 T 的语料,并且加入了多语言的支持。
首创开源新模式,主打一个开放的彻底性
与移动互联网时代手机操作系统比如安卓的开源不同,所谓的大模型开源,通常指的是公开自身的模型权重,很少有企业会选择开源数据比重、数据处理等训练细节。
科研机构、企业和开发者们即使拿到开源权限,也很难进行深入研究。换言之,即使 OpenAI 大发善心马上就将 GPT-4 的参数权重开源出来,从业者们能做的也是在其基础上做一些浅层的微调,想要复刻一个一模一样的GPT-4 根本不可能。
为了更好地助力大模型的学术研究,百川智能公布了3000亿到2.6万亿Token模型训练全过程的Check Ponit。
等于说,百川智能为大模型训练剖开了一个完整的切面,让大家可以更直观的了解到大模型预训练中的量化策略和模型的价值观对齐等具体操作方法,这将为国内大模型的科研工作提供极大助力,这种开源方式在中文大模型领域是首创。
不仅如此,百川智能还在发布会上公开了 Baichuan2-7B 的技术报告。技术报告详细介绍了Baichuan2-7B 训练的全过程,包括数据处理、模型结构优化、Scaling Law、过程指标等。
这一系列彻底开放的操作,相当于重新定义了大模型“开源”,其开源模式或将成为国内“开源”的标杆。以后,“犹抱琵琶半遮面”式的开源将很难再出现。
另一个耐人寻味的事情是,在模型参数和结构设置上,Baichuan开源大模型在尽可能的靠近 LLaMA系列,这意味着用户能够直接从LLaMA换成百川的模型。不难发现,百川智能不仅要在与LLaMA2正面硬刚中完胜,还要来个“釜底抽薪”,简直赢麻了。
如何选择开源大模型,不再是问题
“生存还是毁灭,这是一个值得考虑的问题”,这是《哈姆雷特》中的经典独白。此前,国内企业在模型的选择上面临着同样的挣扎。
OpenAI 并不Open,只提供API调用,让国内从业人员颇为头疼。LLaMA的开源,似乎让国内企业看到了更好的道路,尤其对于中小企业而言,无需从无到有训练一个基础模型,可以极大节省成本。
但使用LLaMA 也面临着两个无解的问题。首先,LLaMA2在商业协议中明确表示不允许英文以外的语言商用,虽然不排除通过合理沟通解决这一问题的可能性,但需要耗费巨大的机会成本。

其次,LLaMA的中文表现差强人意。由于它并非多语言模型,其预训练数据绝大部分使用的是英文数据集,中文预训练数据的占比仅为0.13%,即使使用高质量中文数据集进行微调,中文表现也是惨不忍睹,而且慢得离谱。
除非重新构建数据集中的语料配比,加大中文数据从头进行预训练,否则很难得到大幅提升。而基于大规模中文语料进行预训练,基本和自研大模型无异,从实用的角度来看,LLaMA2并不能满足中文环境的应用需求。
Baichuan2 的开源,无疑将彻底改变这种两难的局面。不论小扎愿不愿意承认,LLaMA在中文世界的时代都已经结束了。
Baichuan 系列开源模型正在引领开源社区走向中文开源大模型时代,百川智能率先在通用人工智能的道路上留下了属于中国人的声音。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!