10月9日,由杨植麟创立的⽉之暗⾯,发布大模型产品——Moonshot AI,以及搭载该模型的智能助⼿Kimi Chat,是全球首个支持20万字输⼊⻓度的大模型。
据杨植麟介绍,Claude支持8万字左右,GPT4 只支持2万字左右。也就是说 Moonshot AI 已经超越了支持 100K 输⼊⻓度的大模型 Claude 以及支持 32K tokens 处理能力的 GPT4 。
其中Claude通过提供⻓⽂本问答服务实现了产品层的突破,并于近期拿下Amazon的40亿美⾦投资。
而⽉之暗⾯在成立不久也已经获得来⾃红杉资本、今⽇资本、砺思资本等知名投资机构近20亿元的融资。
那么杨植麟在国内做大模型的公司里面究竟是一个什么位置呢?
一个硅谷极具影响力的科技媒体The Information列出了其认为有可能成为“中国OpenAI”的五个候选,里面有MiniMax、智谱AI、光年之外以及澜舟科技,而另一个位置就是杨植麟。
杨植麟不仅师从清华教授、IEEE Fellow唐杰。后来他还前往 NLP 研究全球排名第一的 CMU(卡内基梅隆大学)语言技术研究所(LTI),跟随苹果公司 AI 负责人Ruslan Salakhutdinov 和 Google AI 智能首席科学家 William W. Cohen 攻读博士学位。
卡内基梅隆大学计算机专业的博士生往往要经过六年的学习才能毕业,而杨植麟只用了四年(2015-2019)就从CMU出师。
而其团队的核心成员也多出身清华系,有明星团队的光环在身,倍受关注。
杨植麟表示,这次创业瞄准的是ToC赛道,并阐述了创业的三个主要原因:第一,探索智能的边界,满足好奇心;第二,探索的东西对世界有用,和用户共创找到落地的场景;第三,希望AI是普惠的,提供一个更强大的方式,做个性化的结合。

(Kimi Chat内测界面)
1、瞄准ToC赛道
“大模型产品将进入长文本时代,”在媒体沟通会上杨植麟指出。Moonshot AI相信,更⻓的上下⽂⻓度可以为⼤模型应⽤带来全新的篇章,促使⼤模型从 LLM时代进⼊L(Long)LLM时代
“我们认为不光是要有足够多的参数量,同时要有很长的上下文能力,这是标志的新一代大模型的内存。”在杨植麟看来,做好大模型,有两个条件,第一个就是参数量,因为参数量决定了能处理多复杂的计算;第二个条件就是文本长度,因为上下文对应的是计算机的内存。
杨植麟说突破长文本能力是“登月计划”的第一步,也是为之后的多模态能力打基础。他对小编表示,计划明年会推出多模态能力。
Moonshot AI 的技术路线就是不走捷径,踏实解决算法和工程的双重挑战。在杨植麟看来,目前很多长上下文的模型走的是以下三种捷径:鲸鱼模型、蜜蜂模型、蝌蚪模型。
“鲸鱼模型”可以理解为,以滑动窗口的方式,直接主动抛弃了很多上文,虽然号称的范围很长,但是实际上支持的很短,这种鲸鱼模型是很难解决很多任务。
“蜜蜂模型”是关注局部,忽略了全局,虽然可以输入整个上下文,但模型可能只是采样其中的局部。比如一篇文章的关键在中间,那么它就无法提取到关键信息。
“蝌蚪模型”则是能力不够,可能只有10亿的参数量,并不是千亿级别的,所以能力有限。
目前Moonshot AI在存储、算力、带宽,都做了很多的优化,是一个真正可用可产品化的长文本,杨植麟如是说。
2、长文本处理能力惊人
为什么在这场如火如荼的AI大战中,大模型的长文本处理能力成为了各家攀比的关键。
用过大模型产品的朋友应该遇到过这样一个现象:当你和大模型进行多轮对话,聊着聊着它可能就忘了你之前说话的内容,此时回答的内容也比较拉垮。事实上是大模型在处理大量新内容时会有点“力不从心”,因此看起来像是出现了“分心”的现象。
长文本处理是生成式AI的重要应用场景之一,因为良好的长文本处理能力可以让AI系统理解书籍、研究报告、法律文件等足够复杂和冗长的信息,这将为知识获取、文档分析、语义理解等方面带来实用价值。
沟通会现场,杨植麟为我们演示了,Kimi Chat 在提取20万字小说关键信息的能力;可以一口气输入几十个文档进行提取;同时还能输入链接,直接提取链接内的内容,进行角色扮演;另外还可以分析财报,理解法律条文。
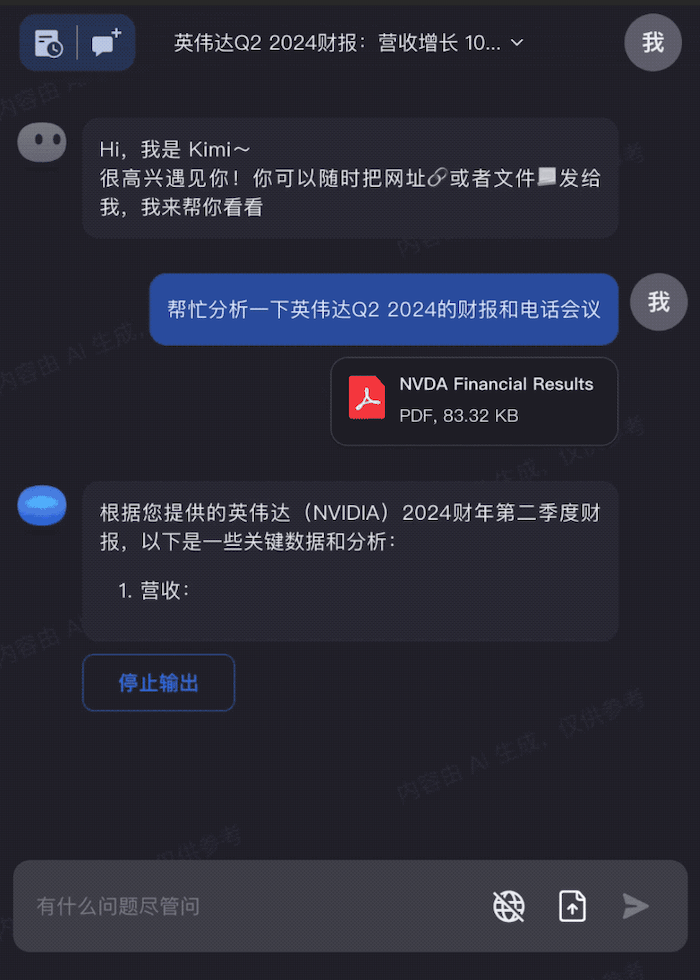
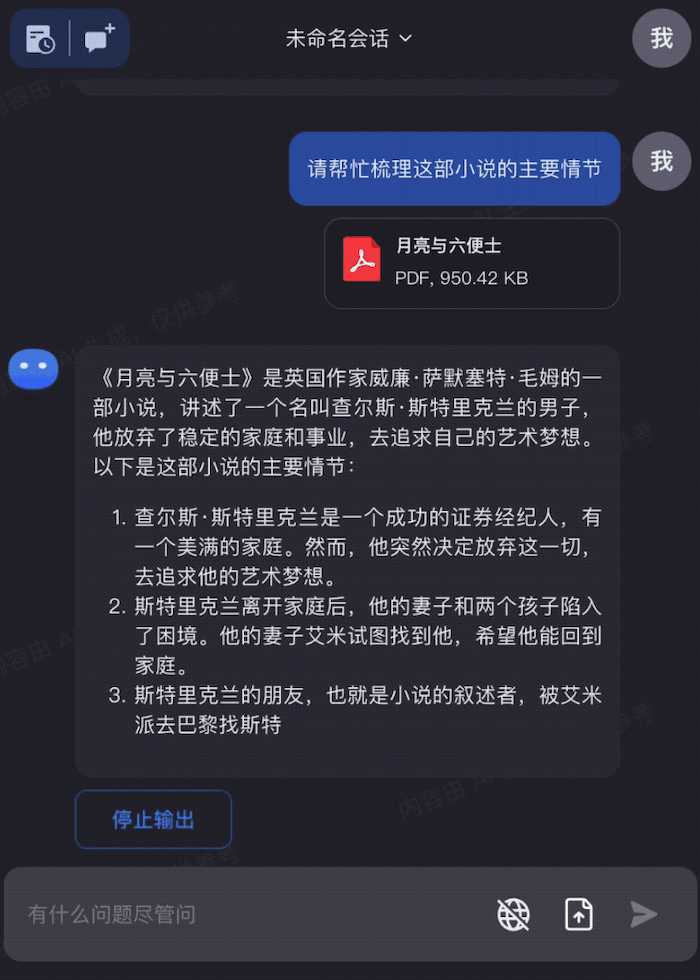
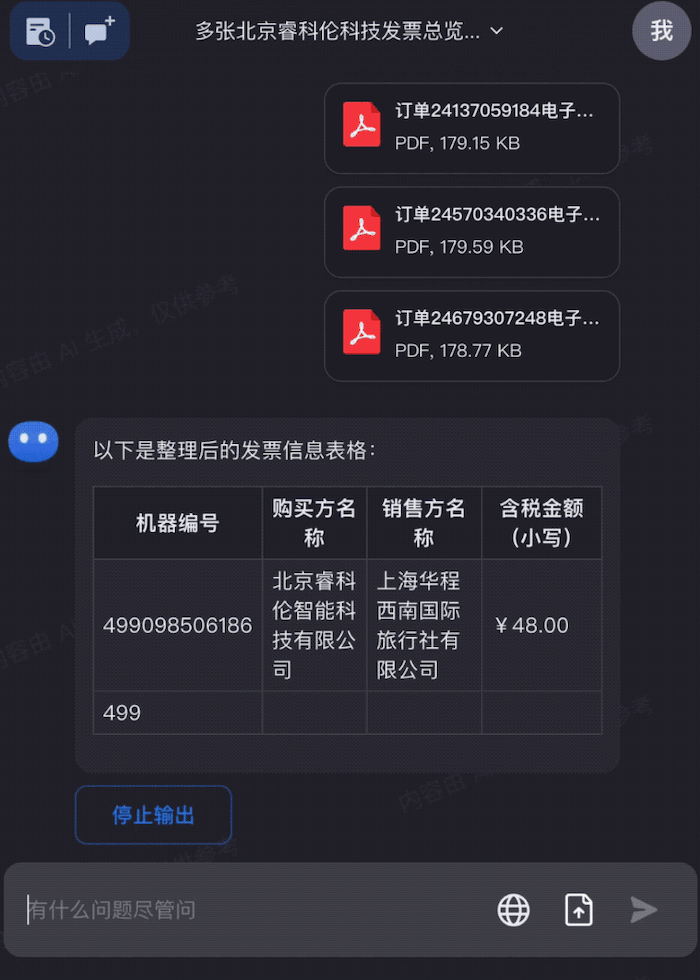
当问及上下文输入过长可能会导致注意力分散问题,杨植麟对小编表示,当你的输入有 20 万字的时候,要让模型准确的去连到某一个 token 上,这个难度肯定是会变大。所以在这里面其实就需要一些更高效的对齐方式,比如怎么去高效地得到好的数据,同时用一个工程化的方式去把它实现出来,这个需要大量的迭代和训练,而传统的鲸鱼、蜜蜂、蝌蚪模型是无法解决这些问题的。
Moonshot AI 突破这些难点的两个关键词是“全局”和“大规模参数”,一方面是要全局地思考上下文,另一方面是用千亿参数来训练,这两点很重要,杨植麟在最后表示。
在小编看来,目前各家大模型还处于你追我赶的争夺赛当中,未来生成式AI的技术竞赛将在长文本处理领域。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!