本科毕业于清华姚班、博士毕业于普林斯顿大学,师从 Sanjeev Arora 教授,马腾宇作为 AI 学界一颗冉冉升起的新星,如今已在国际顶级会议和期刊上发表了 20 篇高质量的论文,曾拿下 2018 ACM 博士论文奖等诸多重量级的学术荣誉。
日前,在北京智源人工智能研究院主办的海外学者报告会上,马腾宇带来了一场干货味十足的报告,不仅基于近期聚焦的研究工作“设计显式的正则化器”分享了理解深度学习的方法,还基于自己的研究经验分享了不少研究方法论和观点。

他指出,现在用来理解深度学习的常用方法是隐式的正则化方法,然而他们在研究中发现,显式的正则化方法可能是更好的选择。
同时,他强调,计算机科学跟物理、生物等传统科学的不同之处在于:可以不断地设计新的算法。“虽然我们无法理解现有的深度学习算法,但我们大家可以设计我们既能理解又能保证有效的新算法。”
我们下面来看马腾宇的报告内容:
一、为什么过参数化的深度学习模型能实现泛化?
深度学习是马腾宇研究组的重要研究方向,他们的主要研究思路是从方法论层面,通过一些数学或理论的分析从技术的角度提高深度学习模型的性能。
他指出,从方法论的层面来看,深度学习当前存在的一个非常核心的挑战就在于需要很大规模的数据才能实现泛化,并且数据量的规模需要大到非常夸张的地步,以至于他认为学术界很难完全收集这么多数据,往往只有工业界能做到。
因此,如果希望深度学习模型减少对数据的依赖,就需要理解如何能用更少的数据来实现深度学习模型的泛化。
那为什么现在过参数化(Overparametrized)的深度学习模型能够泛化呢?
这是因为现在的深度学习模型与之前的模型相比,一个核心区别就在于:此前的传统观点认为,当数据数量远超过参数数量时,模型才能泛化;而在深度学习时代,观点则相反,认为成功的模型应该有更多的参数、更少的数据量。所以现在深度学习模型要实现泛化,需要的参数多于数据量。
然而在深度学习的时代,模型的泛化都非常难以解释,原因就是很多传统的观点并不再适用了。其中有一些传统的观点还是有效的,比如说奥卡姆剃刀定律(Occam’s Razor),指的是低复杂度的模型也可能泛化得很好。
不过这种「低复杂度」其实是很难定义的,因此更核心的问题是如何正确定义模型复杂度,以及我们大家可以通过什么方法能衡量并找到正确定义的复杂度。这是他们希望通过一些理论研究来解决的问题。
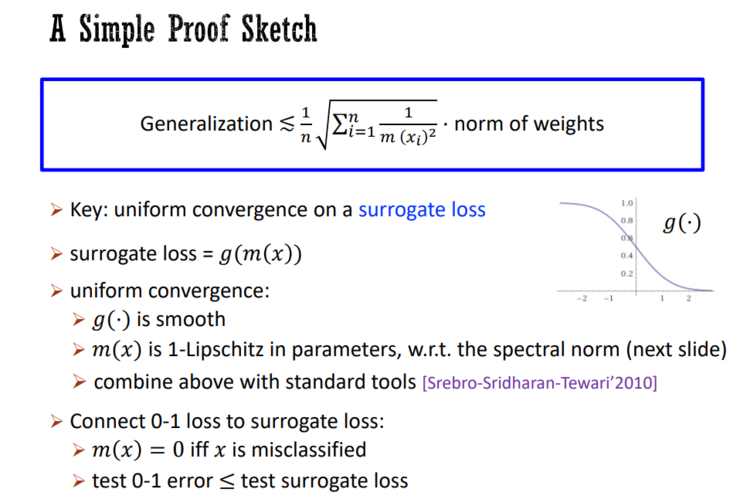
常见的方法是隐式的正则化方法,分析该方法可以聚焦于两个方面:第一,算法更偏好低复杂度的方案;第二,低复杂度的模型泛化得很好。分析好这两个方面,就能够理解现有的算法,同时探索新的度量复杂度的方法——因为算法偏好的复杂度基本就是正确的复杂度度量方法。
马腾宇以其团队开展的一些工作为例阐述了一些发现:
- 第一,在模型训练和收敛方面,学习率至关重要。例如在他们最近的一篇 NeurIPS 论文中证明了,一个使用了大学习率的两层神经网络,只能表示线性的函数,因而即使使用了很复杂的模型,在有噪声的情况下也只能表示一些格外的简单的解,从而使得模型要比想象中更简单些,这其实就是噪声在深度学习中起到了正则化的作用。
- 第二,初始化方法对模型的复杂度,也有同样的效果。例如 Chizat Bach 在 2019 年发表了一篇论文,证明了大的初始化状态更容易得到最小的神经切线核范数解。而他们自己的一些工作,则证明了小的初始化更偏向于得到更加「丰富」的状态,会比核状态更有意思,比如说最小的 L1 解或者原子核范数解。Woodworth 等人有一项工作基本上就说明:一个较小的初始化的模型,会收敛到一个最小的 L1 解而不是 L2 解上。
这些工作的核心思想是,不同的算法有不同的偏好,而不同的偏好则会有不同的复杂度量,学习率会有偏好,初始化状态也有偏好。
二、隐式/算法的正则化是理解深度学习的唯一方法吗?
如果想要理解深度学习,是不是只有理解隐式/算法的正则化这一种方法呢?
对此,马腾宇认为应该要重新回顾一下经典的方法——理解显式的正则化方法。他表示,显式的正则化方法确实也值得被大家关注,而且从短期来讲,它可能是一个更有成效的方法。
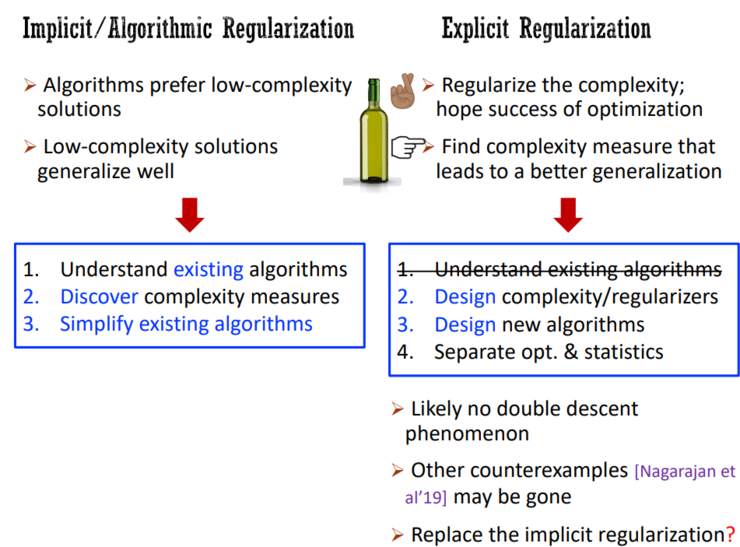
隐式/算法的正则化方法,为了达到要求,需要对算法进行正则化,算法会倾向于得出低复杂度的解。然而从很多算法正则化相关的论文中,他们发现在说明「算法倾向于得出低复杂度的解」方面遭遇瓶颈,而在说明「低复杂度的解泛化得更好」方面则最简单。
因此,显式的正则化方法可能是理解深度学习更好的选择。
在这种经典的机器学习范式下,着重关注的则是研究怎样的复杂度可以让模型实现更好的泛化性能。而对于「算法倾向于得出低复杂度的解」这一研究瓶颈,则「全看运气」。
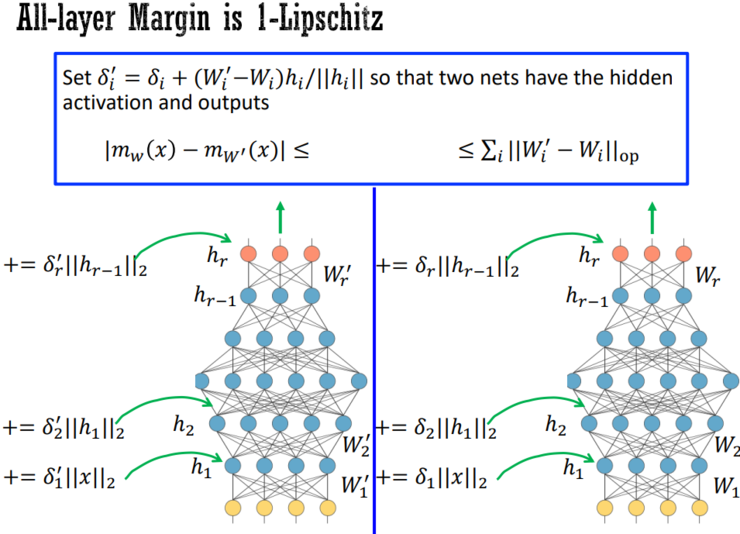
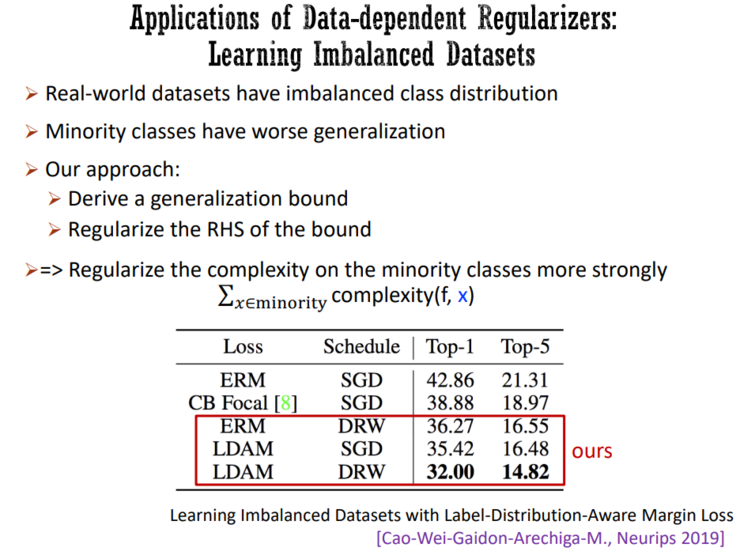
显式的正则化方法的不足点是需要改变算法,因为正则化复杂度势必就会改变算法。然而其优势在于,不仅仅能够理解现有的算法,还可以设计一些新的复杂度度量或正则器,设计一些新的算法,并将优化和统计数据分离开来。
他指出,最近机器学习领域的一个很火的话题是「双重下降」(Double Descent)现象,就是说测试误差并不是单一下降的,而是双重下降。而最近他们在一项工作中,尝试展示的则是在将算法正则化之后,可能就不会再出现双重下降现象。
2019 年 Nagarajan 等人的一篇 NeurIPS 最佳论文奖展示了一致收敛无法说明深度学习中发生的现象。他们举出了一个反例来说明这一点,虽然这个反例非常令人信服,但是仅仅是针对现有算法成立的一个反例。即算法加入正则化之后,这些反例有很大的可能性就不再成立了。
那如何检验是否做到了将优化和统计数据分离呢?
方法则是,模型在正则化目标函数后,不管使用什么算法都能实现同样的泛化能力,这就能说明优化和统计数据分离了。
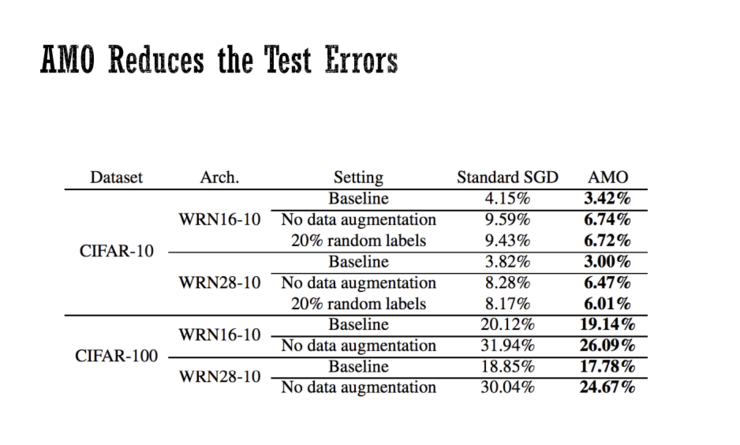
马腾宇表示,他们现在也证明了能够使用显式的正则化方法来替代隐式的正则化方法,虽然还无法完全替代,但他相信正在朝着这个方向前进。
三、无法理解现有的深度学习算法?那就设计一个能理解的!
在当下 AI 界的普遍认知中,深度学习的内在机理无法理解,本质上变成了一个科学问题。对此,马腾宇指出,计算机科学跟物理、生物等传统科学的不同之处在于:可以不断地设计新的算法。
科学研究的内容更多的是世界上已经发生或存在的客观现象(比如黑洞),而在计算机科学中,研究者可以不研究发什么什么,而是去研究任何想要研究的事情。
他呼吁道:「虽然我们无法理解现有的深度学习算法,但我们大家可以设计我们既能理解又能保证有效的新算法。我认为计算机科学领域的研究者可以把研究做得更主动一些。」
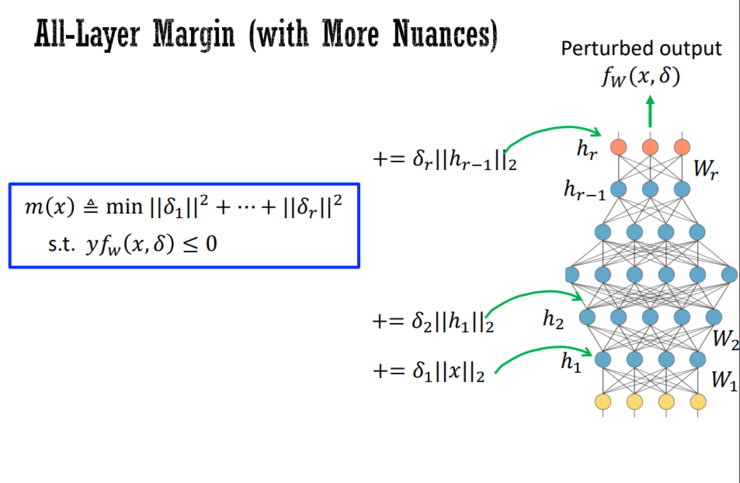
报告中,马腾宇还基于自己近期的研究工作,事无巨细地分享了显式正则化的具体研究示例:







本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!