计算机视觉是人工智能技术的重要应用方向。在深度学习时代,大量以 ImageNet 为代表的数据集被用于训练各种视觉理解模型,从而完成图像分类、目标检测、图像分割、场景理解等任务。在 ImageNet 数据集中,物体往往单独出现在图像的中央区域。然而,真实的视觉世界则要丰富得多。

图 1:ImageNet 数据集
对于人类视觉和计算机视觉而言,在场景的上下文中理解、建模对象是最重要的任务之一。在人类文明发展的长河中,艺术家们逐渐掌握了场景形成的规则,并发展出了超现实主义等艺术流派,能够熟练打破这些规则。他们能够对场景中的各种视觉元素进行解构、重组、艺术化加工,从而创作出新颖而又能够被人类所理解的艺术作品。

遗憾的是,在深度学习时代,面向分析和合成任务的场景建模并没有得到足够的重视。有时,我们采用和对象建模类似的自顶向下方式建模场景,例如:对于 GAN 或图像分类器而言,「卧室」和「厨房」等场景类别的表征方式与「床」或「椅子」的表征方式类似。有时,我们又采用和语义分割任务类似的自底向上的方式为图像中的每一个像素赋予语义标签。
然而,对于场景理解而言,上述两种方法都不尽如人意,它们无法将场景中的各个部分作为实体,从而进行简单的推理。场景中的部分要么被融合为一个耦合的潜向量(自顶向下),要么需要根据独立的像素标签聚合在一起(自底向上)。
为此,在资深计算机视觉学者 Alexei A.Efros 教授的指导下,来自 UC Berkeley 和 Adobe 的研究人员近期发布了论文「BlobGAN: Spatially Disentangled Scene Representations」,为场景生成模型提供了一种介于像素和图像之间的无监督中间表征。在该工作中,研究者们将场景建模为在空间、深度上有序的高斯 Blob 连通区域的集合。
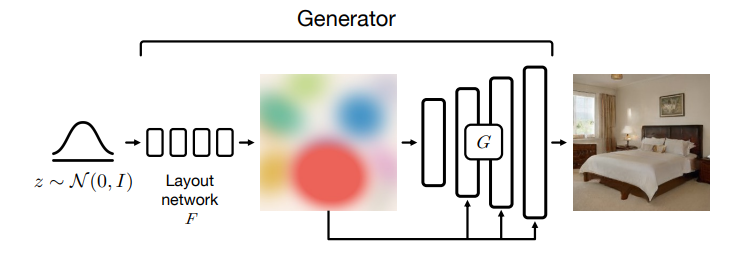
图 3:BlobGAN 模型架构
如图 3 所示,这些 Blob 的集合处于生成器架构的「瓶颈」处,迫使每个 Blob 对应于场景中的一个特定对象,从而产生在空间上解耦的表征。如图 4 所示,在该模型的帮助下,我们可以在没有语义监督的情况下完成许多场景编辑任务。
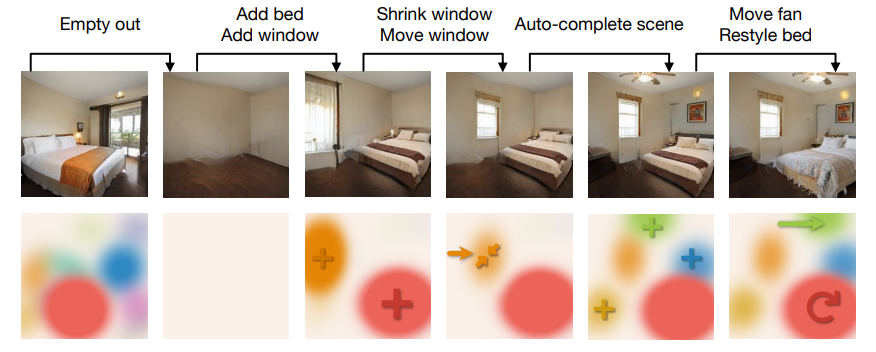
图 4:利用 BlobGAN 完成的场景编辑任务。
目前,该工作在 Reddit 上引起了热议,许多网友们纷纷为 BlobGAN 的惊人表现而折服。
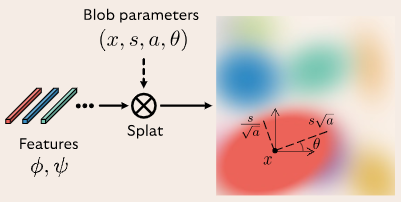
BlobGAN 的实现方法充分体现了深度学习和基于手工设计的传统计算机视觉方法的结合。如图 1 所示,在 BlobGAN 中,满足标准正太分布的随机噪声 z 会被输入给一个布局网络 F,布局网络会将噪声映射为一组描述 Blob 的参数 β(见图 5)。Blob 可以作为一种强大的中间生成表征。接着,我们将 Blob 可微地描绘在空间网格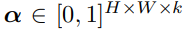 上,该网格也描述了 Blob 的透明度。接着,我们利用一个类似于 StyleGAN2 的解码器 G 将其转化为逼真、和谐的图像。我们使用一个不会被修改的判别器在对抗框架下训练模型。在没有显式标签的情况下,我们的模型可以学会将场景中的实体及其布局解耦开来。
上,该网格也描述了 Blob 的透明度。接着,我们利用一个类似于 StyleGAN2 的解码器 G 将其转化为逼真、和谐的图像。我们使用一个不会被修改的判别器在对抗框架下训练模型。在没有显式标签的情况下,我们的模型可以学会将场景中的实体及其布局解耦开来。
算法细节
具体而言,椭圆 Blob 的参数包含 Blob 的中心坐标 x ∈ [0, 1]^2、尺度 s ∈ R、纵横比 a ∈ R、旋转角度 θ ∈ [−π, π]。每个 Blob 都带有一个结构特征 和风格特征,我们在将 Blob 转换为 2D 特征网格时会用广播的矩阵乘法操作将两个特征向量。Blob 表征可写作:
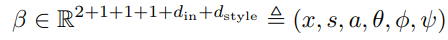
在得到了 Blob 后,我们以 StyleGAN2 为基础构建了生成器 G 将 Blob 转换为真实、和谐的图像。在这里,我们基于 Blob 的结构特征采用了岁空间变化的输入张量,而不是单一、全局的向量,并进行了随空间变化的调制。标准的 StyleGAN 要求每个风格向量 w 必须囊括场景所有方面的信息,而 BlobGAN 则可以将布局和外观解耦开。
直观地说,Blob 内的所有激活值都由相同的特征向量控制,促使 Blob 产生自相似属性的图像区域(场景中的实体)。此外,由于卷积是局部的,输入中的 Blob 的布局必须很强地包含图像区域的最终组织的信息。最后,我们的潜空间通过构造过程将 Blob 的布局与外观解耦。这有助于我们的模型学会将单个 Blob 与不同的对象绑定,并将这些 Blob 组织到合理的布局中,从空间上将场景分解为一系列组成部分。
BlobGAN 学习到的表征可以从空间上解耦场景。下面,我们分别从定量和定性的角度展示 BlobGAN 如何将 Blob 与场景中的某个目标对应起来,并展示学到的表征如何捕获场景布局的分布。
如图 4 所示,我们对模型生成的图像的 Blob 图进行一系列的修改,例如:清空场景中的实体、增加床和窗户、缩小窗户、移动窗户、自动补全场景、移动吊扇、改变床的风格。BlobGAN 可以灵活地编辑场景。
场景编辑可视化结果
具体而言,BlobGAN 可以将复杂的场景图像分解为组成它们的物体。无监督表征使我们可以很容易地在场景中重新排列、移除、克隆和重塑物体。如图 6 所示,通过修改某些 Blob 的坐标,重新组织卧室中的家具。由于表征是分层的,我们可以建模家居之间的遮挡关系。

图 6:移动 Blob 从而重新组织物体
图 7 展示了从表征中完全删除某些 Blob 的影响。尽管在训练数据中,没有床的卧室非常罕见,但通过移除相应的 Blob,可以将床从场景中移除。我们也可以以同样的方式移除窗户、灯具和风扇、画作、梳妆台和床头柜。

图 7:移除 Blob
BlobGAN 生成的表征使我们可以进行跨图像的编辑。在图 8 中,我们通过交换 Blob 的风格向量高度模块化地重新装配了场景。例如,在不改变布局的情况下,我们将某一场景下的床单风格与另一场景下的床单风格交换。

图 8:交换 Blob 风格
如图 9 所示,如果我们想要引入新的 Blob,可以在新的位置上复制粘贴相同的 Blob,形成新的布局。

图 9:复制粘贴 Blob
定量的 Blob 分析
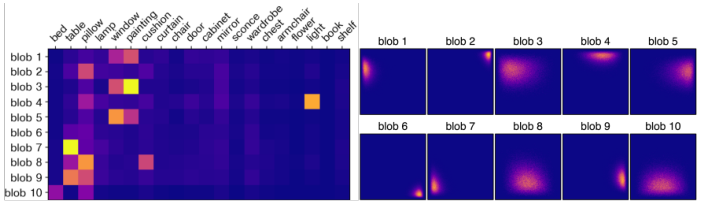
Blob 和场景中的实体具有很强的关联。我们通过将 Blob 的尺寸参数 s 随机设置为负数来删除它。然后,我们使用分割模型观察消失的语义类。图 10(左)展示了类和 Blob 之间的相关性。该矩阵十分稀疏,这表明 Blob 随着学习专门对应到不同的场景实体。图 10(右)展示了 Blob 的中心的分布。合成的热力图展示了训练数据中物体的分布。模型会学着在特定的图像区域定位 Blob,通过改变风格向量控制表征的物体。
将 Blob 组合到布局中
除了将图像分解为若干部分,理想的场景表征还需要捕获各部分之间丰富的上下文关系,这些关系决定了场景的生成过程。BlobGAN 的表征可以显式地发现场景中物体的布局。
在测试时,我们通过求解一个简单的约束优化问题,可以对满足底层场景约束的展示图像进行采样,进行「场景自动补全」。如图 11 所示,不同的空房间具有各自的背景向量 ,以及由潜变量 z 生成的装饰,我们通过优化合理地装饰场景,使之与背景向量相匹配。
,以及由潜变量 z 生成的装饰,我们通过优化合理地装饰场景,使之与背景向量相匹配。

图 11:生成并填充空房间。
通过使用布局网络 F 对满足 Blob 参数子集约束的不同场景进行采样,我们可以进行带条件的场景自动生成/补全。图 12 展示了特定布局条件下的风格生成、根据床和梳妆台的位置和大小预测可信的场景。比起使用 F 自动补全场景,我们还可以生成一个随机的场景并简单地替换感兴趣的参数以匹配所需的值。我们可以对场景进行物体的插入、移除、方向调整。

图 12:场景自动补全
我们通过替换目标图像中的属性来编辑图像,这些属性要么是随机生成的,要么是使用模型进行条件采样得来的。通过改变网络深度,我们切换 StyleGAN 中的风格。为了进一步保持全局布局并提高一致性,我们的模型还可以使用源图片中的结构网格 Φ。我们通过 FID 来评估模型生成样本的多样性和质量。在所有情况下,BlobGAN 的场景自动补全性能都优于基线。
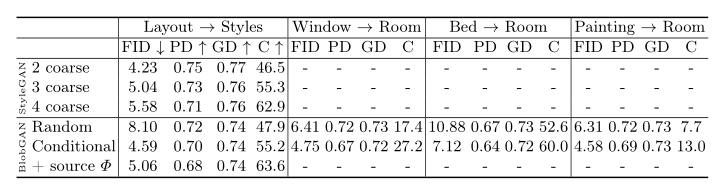
表 1:自动补全的定量分析结果
BlobGAN 可以在 LSUN 房间中获得与 StyleGAN 相媲美的视觉质量。BlobGAN 生成的样本更加逼真。
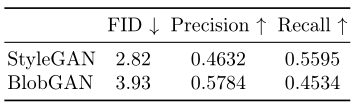
表 2:评估视觉质量和多样性
区域级图像解析
BlobGAN 得到的表征还可以通过将图像反演到 Blob 空间来解析这些真实图像。我们可以移除并重新定位真实图像中的物体,发现其与原始图像的差异。

图 13:通过反演解析真实图像
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!