ATEC2022比赛背景

科技促进产业数字化,是数字时代经济发展的重要命题。本届ATEC科技精英赛,通过考察选手对图学习、隐私计算、多模态识别、智能推荐等核心技术的掌握能力,解决营销数字化、产品数字化、融资数字化三大现实问题。帮助企业抵御安全风险、提升数字化运营能力,帮助从一个全新的数据维度来实现农作物的数字化,借助数字化技术提高农村金融的资金匹配效率、极大地助力农业产业的持续发展,做到了“科技助实”。
赛题一——营销数字化
赛题解读
提高中小商家的数字化经营能力,是我国数字经济做强做优做大的关键基础,也是推动数字技术与实体经济深度融合的关键路径之一。中小商家通过数字消费券的配置与分发,为店铺带来了许多潜在的客户,好的数字化运营策略可以帮助中小商家提升用户的留存与消费意愿,同时带来更好的收益与经营效率。本赛题便是围绕营销数字化的主题,考察选手如何从海量的用户线上线下行为中挖掘可帮助中小商家进行数字化营销的有效信息,帮助其提高商品的分发能力。
本赛题会向选手提供一段时间内消费券向用户展示和被用户领取的数据,并要求选手预测在这段时间以后不同用户在多个中小商家的候选商品集合中,更有可能点击哪些商品。除此以外,为了尽可能还原真实的工业数据环境,本赛题还会向选手提供用户和消费券的基础特征、支付宝全域用户行为、实体间关联图谱等数据,同时确保这些数据的采集和构造都是发生在待预测时间段之前。所有的数据都经过了严格的脱敏,以保证用户隐私信息的安全性。
和一般的点击率预估任务不同,我们提供了十倍于私域行为(用户在中小商户内的交互行为)的全域用户行为(例如搜索、账单、足迹等),而比赛又是仅仅只有 9 小时的个人赛,这十分考验选手的基本功,以及选手在如此丰富的数据类型下的模型选型与迭代思路,赛题讲究快、准、稳,稍有迟疑便会落后。为了让训练速度不成为选手快速提分的瓶颈,我们提供了 12C92G + V100 的运行配置。
比赛观察
本次比赛的数据种类多,且时间紧张,选手如何快速的迭代并拿到收益决定着他是否能够晋级并有机会拿到百万大奖。比赛属于个人赛,这非常考验选手的基本功底,但能够从线上赛的选拔中脱颖而出,也说明每一个选手都是有自己突出的优点。
在这些因素的限制下,几乎所有的选手都选择了将树模型作为自己的基线,并通过对数据的一系列特征工程为该基线注入许多新的信息,从而帮助模型更好的预估用户的点击并达到提分的效果。相比于深度学习中模型调参与拟合 label 的过程,树模型有着更方便、快捷、开箱即用的优点,且无需担心像深度学习中由于参数或网络层设计不合理而导致的模型效果差的问题。因此,树模型的热度在竞赛圈也一直是名列前茅的。
在比赛中,更细致更全面的从各个角度来挖掘用户与商品的潜在信息,也决定了该做法能带来的增益大小。高排名的选手有着丰富的竞赛经验,无一例外地为比赛所提供的信息选择了更适合处理它的策略。在实际业务中,不可避免的存在许多经过脱敏、缺失或无意义的信息在内,因此选手的数据素养与特征分析能力对比赛的良性迭代会起到非常关键的作用,高排名选手会在数据分析后通过清洗、去噪、加权等策略帮助模型对有效信息的充分利用。此外,快速的迭代也能够帮助选手更快的找准提分的方向,并为下一阶段的尝试方向做好预估,这也是选手间能够拉开比赛差距的重要原因。
本次比赛采用半封榜的机制,在前期每个选手仅能得知自己的排名是否处于赛道末位的四位,而在后期该信息完全不可知。选手在紧张的氛围下承受着对自身排名不明确的双重压力,这也促使每个人不断地向前。双重压力下,心态好的选手镇定自如,即使处于淘汰边缘也一心做题,而心态差的选手在后续比赛中频繁失误(不论是 bug 出现次数,或者是迭代进展变缓)。这也是每一个竞赛选手必须经历的考验之一,百般磨炼,终能独挡一面。
赛题二——产品数字化
(水稻 or 小麦?从遥感农作物识别到农业金融)
赛题解读
2019年,农业农村部提出数字农业农村发展规划(2019-2025),明确提出以农业数字化为重点发展主线,全面提升农业农村生产智能化、经营网络化、管理高效化、服务便捷化水平,以数字化引领驱动农业农村现代化,为实现乡村全面振兴提供有力支撑。这其中对核心主粮作物、经济作物种植区域进行数字化建模是实现农业数字化的基础一环。
依托现代卫星遥感技术,我们可以实现对丰富的农作物信息的识别与提取,例如农田植被状况、土壤湿度、气候变化等。对地物目标进行多光谱、多时段监测,可以获取大量信号特征,同时基于不同农作物对不同波段光谱的特异性反射差异、生长周期特点,可以实现低成本、高精度、大范围的农作物种类识别,为实现农业数字化生产、高效网格化经营提供基础数据,从而应用于农业信贷、农业保险理赔、宏观农业种植监控等领域。
本次赛题的图像数据来自开源多光谱卫星提供的时序多光谱影像,农作物(水稻、玉米、大豆)标签来自田野实地调查获取的数据。主要目的是通过时序多光谱遥感数据序列,设计人工智能算法,识别出对应地点对应时间段的种植农作物种类。对于遥感农作物识别,光谱反射特性以及农作物生长周期特性是两大关键特征。此外,数据中的地表分类层(SCL)字段中还包含了粗分类的标签,包括云层、水体、植被,可以提供有效的先验信息辅助识别。为了帮助选手理解赛题,我们另外提供了基于近红外(NIR)和红光(R),计算植被指数,这也是我们对于选手的“提示”,如何利用农业光谱知识设计特定特征来提升模型识别效果。
比赛观察
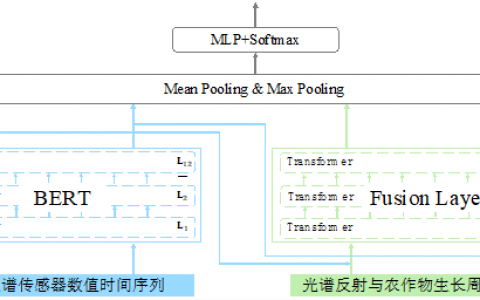
这是一道典型的时序预测赛题,比赛中大部分方案是基于先进的Transformer结构(例如BERT、RoBERTa等),训练多个模型,再利用LGBM进行模型集成。另外对数据的处理上不同的选手也有不同的策略,最终结果除了单纯模型因素之外,对数据和赛题的持续探索也起到了关键作用。
1) 时序建模:处理时序预测的基础是建立一个能对时序数据进行有效建模的模型。在前期尝试了LSTM、MLP、树结构之后,大部分队伍迅速收敛到基于Transformer的模型结构上。Transformer是目前处理序列数据比较成熟的方案,通过将序列中的每个元素看做token,按顺序送入模型中进行self-attention和cross-attention计算,获取有效的时序信息进行任务学习。大部分选手选择BERT或者RoBERTa这类比较成熟的Transformer结构来使用。由于对模型的熟悉程度和具体实现的不同,效果有所差异
2) 特征构建:遥感领域对大部分选手来说都是首次接触,其具有一定的领域特性。部分选手在前期进行了大量数据分析的工作,并得到了一些有效构建特征的方法。例如本次农作物识别的赛题,时间月份、云雾遮挡都会极大影响识别效果。通过对数据去云处理、构建时间月份相关的learnable embedding都可以有效提升识别效果。此外,遥感相关的一些特征,例如ndvi指数计算等,都可以作为有效的特征使用。
3) 模型集成:模型集成的方法在比赛中一般被认为是脏活累活,但却是刷点的“神器”。利用LGBM对多个基础模型结果进行集成学习,往往可以得到更好的结果。在比赛的最后3分钟里,依然有选手在尝试各种模型集成的组合和优化方式,并成功在最后时刻实现了反超。
在蚂蚁的真实场景中,多光谱时序数据是农作物识别中最重要的数据源,此外我们还会使用高清影像、SAR雷达影像辅助农作物识别。在赛题中我们也提供了一部分没有标注的影像数据用于无监督预训练基础识别模型。在实际场景中我们拥有海量的无标注影像数据,为预训练提供了广阔空间。在经济作物识别场景,通过预训练可以有效降低对标注数据的需求,并提升模型识别效果。
赛题三——融资数字化
赛题解读
提升乡村普惠金融服务覆盖面和便利性,持续加大对“三农”领域的金融支持力度,是我国全面推进乡村振兴的重点工作之一。在农村振兴相关领域贷款投放方面,金融机构发挥着重要的作用,通过向农村产业链的经营者发放贷款,可以满足乡村振兴生产经营融资需求,缓解“融资难”等问题。
然而涉农经营者信贷风险管理有其特殊性,需根据特定的行业风险点,制定相应的风险评估防范策略,提升智能化风险管理水平。本赛题将探索农村金融中一个基础问题,即如何利用数字化技术来识别农村经营者的经营状况和经营风险,其也是帮助农村经营者进行融资的基础能力之一。
基于这样的背景,我们主要围绕涉农经营者风险评估这一关键问题,考察选手如何利用涉农经营者特征以及非结构化数据,如用户交互关系等,来帮助提高涉农经营者的风险评估模型的精度。
在本次赛题提供的数据中,不仅有部分涉农经营者的风险相关,如信贷行为信息;还提供了用户多源的交互关系,如涉及用户收付款相关的序列行为、用户交互关系等。要求选手预测农村经营者在未来将存在的潜在经营风险。考虑到农村地区数字化程度普遍偏低,其数据基础较薄,特征比较稀疏,因此选手们会如何充分利用非结构化数据做好建模以及提取到有效信息,是本赛题的一个重要考察点。
观察记录
区别于前几道赛题,本题目有几个重要的特点:首先,正如实际业务中的情况,提供的特征数据内容比较稀疏,同时测试集ID不能用来对齐训练和测试数据的,因此基础的特征工程角度提升空间有限。其次,本赛题提供了丰富的用户交易序列数据和交互行为数据,可以使用这些非结构化数据对用户信息进行传递,因而可以考虑使用图神经网络进行建模。
实际上,一些典型的与用户交易关系、操作行为相关的欺诈类风险检测问题,包括和金融相关的风险,都通常可以使用图神经网络进行建模。图神经网络建模,一方面可以充分关系数据构图,使用结构数据刻画用户之间的关系与相似性,此外沿着网络拓扑结构对邻居节点的特征进行传播和聚合,还可以缓解特征缺失的问题,并且高阶的关系数据也是对风险预测有很重要的作用的。
从对选手实际比赛中来看,在时间紧张的情况下,对图神经网络熟悉和结构数据熟悉的队伍会有比较大的优势。并且在实际操作过程中,几乎所有选手都发现了充分利用非结构化数据构图的必要性,但在实现上,两队分别采用了不同的策略,一队能够快速地搭建大规模数据下图神经网络的采样、以及卷积的框架,另一队则是以树模型为主,人工聚合邻居特征为辅的形式来替代图神经网络的卷积过程进行特征提取。
此外,该赛题全过程中采用封榜的机制,每队选手仅能得知对方队伍分数是否有提升,并不知道自己的排名,这为双方选手均带来了一定的心理压力和竞争压力。而对于采用不同策略和方法进行图数据建模的选手,最终谁能够在比赛中获得胜利,也是令人期待的。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!