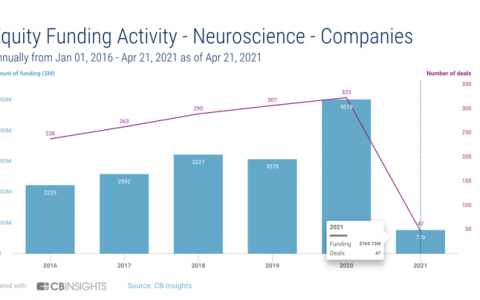
本月,OpenAI、谷歌和Anthropic在短短几天内相继宣布了专门的医疗AI功能,这种扎堆发布的情况表明,这更可能是竞争压力所致,而非时间上的巧合。然而,这些发布的产品均未获得医疗器械认证,未获准用于临床,也无法直接用于患者诊断——尽管其营销话术强调了对医疗健康的变革。
OpenAI推出了ChatGPT Health,于1月7日上线,允许美国用户通过与b.well、Apple Health、Function和MyFitnessPal的合作连接医疗记录。谷歌发布了MedGemma 1.5,于1月13日推出,扩展了其开放医疗AI模型,可解读三维CT和MRI扫描图像,以及全切片病理图像。
人类学随后于1月11日推出面向医疗保健领域的Claude,提供符合HIPAA规定的连接器,可连接CMS覆盖数据库、ICD-10编码系统和国家提供者标识符注册表。
这三家公司都瞄准了相同的工作流程痛点——预先授权审核、理赔处理、临床文档——采用了相似的技术方法,但市场策略各不相同。
开发者平台,而非诊断产品
其架构上的相似之处引人注目。每个系统都使用了在医学文献和临床数据集上微调过的多模态大型语言模型。每个系统都强调隐私保护和监管免责声明。每个系统都将自身定位为辅助而非替代临床判断。
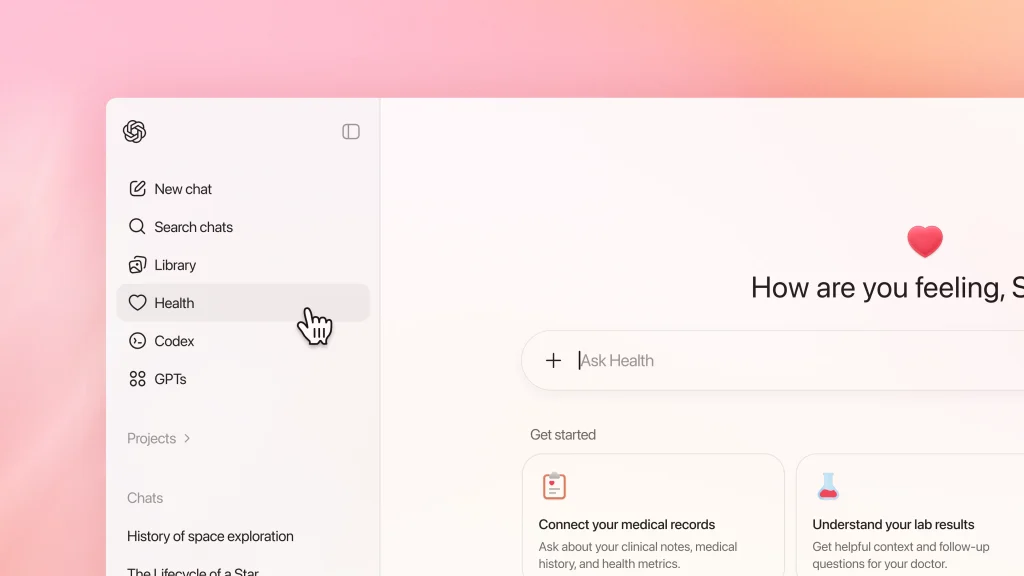
差异主要体现在部署和访问模式上。OpenAI 的 ChatGPT Health 面向消费者提供服务,针对 EEA、瑞士和英国以外地区的 ChatGPT 免费版、Plus 版和 Pro 版订阅用户设有候补名单。Google 的 MedGemma 1.5 则通过其 Health AI Developer Foundations 计划作为开源模型发布,可通过 Hugging Face 下载,或通过 Google Cloud 的 Vertex AI 进行部署。
Anthropic的Claude医疗版通过企业版Claude集成至现有工作流程中,目标客户是机构采购方而非个人消费者。三者在监管定位上保持一致。
OpenAI明确声明其健康产品”不适用于诊断或治疗用途”。Google将MedGemma定位为”开发者评估并适配其医疗应用的起点”。Anthropic则强调输出内容”不适用于直接指导临床诊断、患者管理决策、治疗建议或其他直接临床实践应用”。
基准性能与临床验证
医疗AI的基准测试结果在三个版本中均有显著提升,尽管测试性能与临床部署之间的差距依然显著。谷歌报告称,MedGemma 1.5在斯坦福大学的医学代理任务完成基准测试MedAgentBench上达到了92.3%的准确率,而之前的Sonnet 3.5基线仅为69.6%。
该模型在内部测试中,MRI疾病分类提升了14个百分点,CT发现提升了3个百分点。Anthropic的Claude Opus 4.5在启用Python代码执行的MedCalc医学计算准确率测试中得分为61.3%,在MedAgentBench上得分为92.3%。
该公司还声称在与事实性幻觉相关的“诚实度评估”方面有所改进,尽管并未披露具体指标。
OpenAI 尚未发布针对 ChatGPT Health 的具体基准对比数据,而是指出“全球每周有超过 2.3 亿人在 ChatGPT 上询问与健康和保健相关的问题”,这一数据基于对现有使用模式的去标识化分析。
这些基准测试衡量的是在精选测试数据集上的性能,而非实际临床结果。医疗错误可能带来致命后果,因此将基准准确率转化为临床实用性比其他人工智能应用领域更为复杂。
监管路径尚不明确
这些医疗AI工具的监管框架仍不清晰。在美国,FDA的监管取决于预期用途。用于“支持或向医疗专业人员提供关于疾病预防、诊断或治疗的建议”的软件,可能需要作为医疗器械接受上市前审查。目前宣布的工具均未获得FDA批准。
责任问题同样悬而未决。当Banner Health的首席技术官Mike Reagin表示该医疗系统“被Anthropic对AI安全的关注所吸引”时,这涉及的是技术选型标准,而非法律责任框架。
如果临床医生依赖Claude的预授权分析,而患者因延误治疗受到伤害,现有判例法在责任分配方面提供的指导十分有限。
监管方法在不同市场间存在显著差异。尽管FDA和欧洲医疗器械法规为软件作为医疗器械提供了既定框架,但许多亚太地区的监管机构尚未针对生成式人工智能诊断工具发布具体指导。
这种监管模糊性影响了医疗基础设施缺口本可能加速实施的市场的采用时间表——在临床需求与监管谨慎之间造成了张力。
行政工作流程,而非临床决策
实际部署仍需谨慎规划。诺和诺德内容数字化总监Louise Lind Skov表示,他们正在利用Claude进行“制药研发领域的文档与内容自动化”,主要针对监管申报文件,而非患者诊断。
台湾健保署将MedGemma应用于提取3万份病理报告数据,用于政策分析,而非治疗决策。
这一模式表明,机构采用医疗AI主要集中在错误风险较低的行政流程上——如计费、文档处理、协议起草——而非能对患者预后产生最显著影响的直接临床决策支持。
医疗AI能力的发展速度超过了部署机构应对监管、责任认定及工作流程整合复杂性的能力。技术本身是存在的。每月20美元的订阅费即可获得先进的医疗推理工具。
这是否能转化为医疗保健服务的变革,取决于这些协调发布的公告未能解答的问题。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!