
科技巨头们时不时就声明在 AI 领域取得了突破性进展,对此我们已见惯不惊了。
当地时间 2020 年 1 月 28 日,Google 在一篇博客中介绍了一款开放领域聊天机器人 Meena,号称“史上最强”,那么这一新突破会让人眼前一亮吗?

开放领域聊天机器人开发难度大
实际上,设计智能聊天机器人是为了应对信息爆炸时代存在的信息过载问题。最初,人们把聊天机器人当作搜索引擎的终极形态进行设计和开发。不同于现有的搜索引擎,聊天机器人可针对用户的问题自然又通顺地给出精准的答案,节约了很多时间,从而带来更好的使用者真实的体验。
根据使用场景划分,聊天机器人(chatbot)主要有开放域型(Open-Domain)和任务导向型(Task-Oriented)两种。
其中,任务导向型主要有问答系统、对话系统聊天机器人,分别指基于用户的问题给出一个回答(常用于智能搜索、智能家居中的家电控制等场景)和与用户进行多轮对话的聊天机器人(如客服机器人,销售机器人等)。
而开放领域聊天机器人(也称闲聊式机器人)顾名思义针对开放域的对话场景,主题、内容不限,比如微软小冰和苹果 Siri。Google 在上述博客中表示:
开放领域聊天机器人的研究不仅具有学术价值,还可激发很多有趣的应用,如更深层次的人机交互、提升外语训练效果,以及制作交互式电影和游戏角色。
值得一提的是,开放领域聊天机器人更符合人们心中对「人工智能」的定位,开发难度自然也很大——当前开放领域聊天机器人面临的一个严峻问题在于它们表达的内容往往没有意义,无法与用户的问题连贯起来,而且由于缺乏基本的常识和认知,不能给出针对性的回复。
而 Google 开发的 Meena 正是一款开放领域聊天机器人,那么相比现有的聊天机器人,究竟有何突破?
26 亿参数的端到端神经对话模型
Google 在博客中介绍称,Meena 是个 26 亿参数的端到端训练的神经会话模型,是 GPT-2 模型最大版本(15 亿参数)的 1.7 倍。据称,Google 利用 400 亿字的数据集,通过 2048 个张量处理单元(即 Tensor Processing Unit,Google 专用 AI 芯片)训练了 30 天,得到了最佳版本。实验表明,比起聊天机器人 SOTA,Meena 能更好地完成对话,内容也更具体、清楚。
据悉,Meena 由 1 个 Evolved Transformer 编码器和 13 个 Evolved Transformer 解码器组成:编码器用于处理对话语境,有助于 Meena 理解对方的话;而解码器则会利用信息生成回复。而在这一过程中,Google 表示:
研究人员发现,超参数调整后,实现高质量对话的关键在于性能更强的解码器。
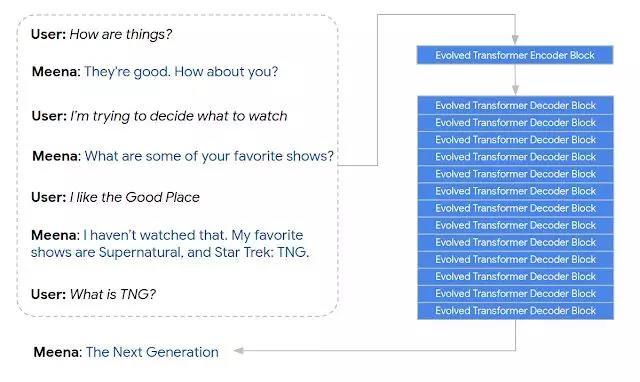
Google 从公共领域社会化媒体对话上过滤得到了 341GB 的文本,并以树状脉络形式组织文本进行「多轮对话」训练。研究者将每轮对话作为训练样本,同时每轮之前的 7 轮对话为语境信息,共同构成一组数据。据悉,选择 7 轮对话作为语境,既能保证训练过程获得足够长的语境信息,同时模型也能不超过内存限制。毕竟文本越长,占用的内存也越多。
新提出的人类评价指标 SSA
根据博客,上述这些表现是由 Google 根据新提出的人类评价指标「Sensibleness and Specificity Average (SSA)」得出的,而此次提出新的指标是因为,目前聊天机器人的人类评价指标颇为复杂,而且也很难形成一致的评价指标。Google 表示,SSA 能捕获基本的、但对人类对话来说很重要的属性。
为计算这一指标,研究者测试了 Meena、Mitsuku、Cleverbot、DialoGPT 及小冰等常见的聊天机器人。在测试中,对于每一款聊天机器人,研究者都在 100 个对话中收集了 1600 到 2400 轮,各聊天机器人的回复都由人类评价者评分(主要依据对话的流畅性和回答的准确性),其各自性能表现如下图。
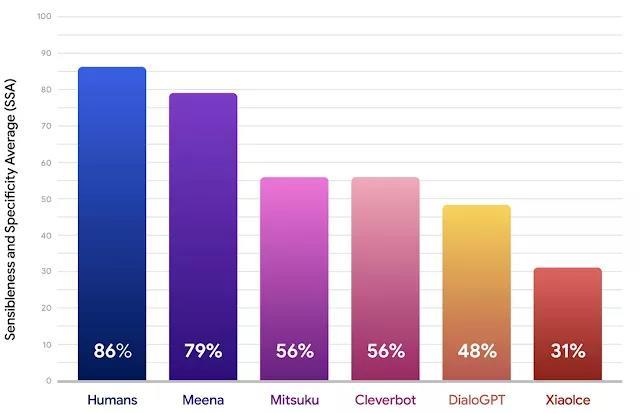
不难看出,Meena 相比于现有的 SOTA 聊天机器人,有着更高的 SSA 分数,甚至接近于人类的表现。
困惑度与 SSA 强相关
毫无疑问,人类评价或多或少存在一些问题,因此很多研究者都希望找到一个能够自动计算的评价指标,而且这个指标要能和人类评价准确对应。
困惑度(perplexity,指一种任何神经会话模型都能轻易获得的计算指标)是 seq2seq 模型(一种循环神经网络的变种,包括编码器和解码器两部分,是自然语言处理中的一种重要模型,可用于机器翻译、对话系统、自动文摘)中的一个常见指标,用于评价语言模型的不确定性。
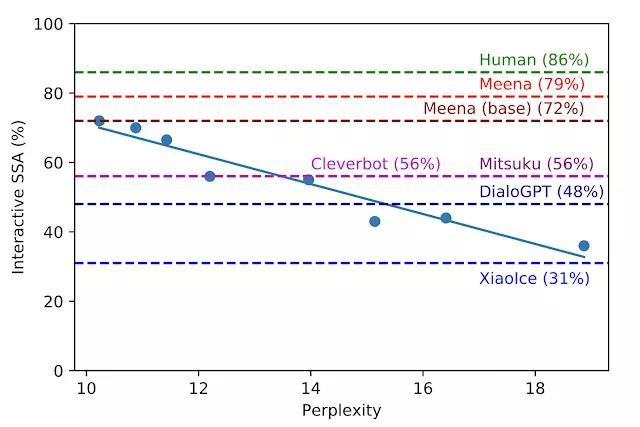
而值得一提的是,Google 证明了困惑度与 SSA 高度相关。
实际上,训练 Meena 正是为了最大程度地减少困惑度,以及预测下一个标记 (注:指对话中的下一个单词)的不确定性——据博客称,是因为 Meena 的核心为 Evolved Transformer seq2seq 架构,即一种通过进化神经架构搜索发现的 Transformer 体系结构,能够改善困惑度。
在博客中 Google 表示,研究者依据层数、注意力数量、训练步数、编码器、训练方式等因素,共测试了 8 种不同的模型,发现困惑度越低,SSA 分数越高,同时两者的相关系数很高(R^2 = 0.93)。
同时 Google 表示:
研究者将继续通过改进算法、架构、数据和计算量等,降低这一神经会话模型的困惑度。
Meena 意义大吗?
根据博客中展示的数据,我们相信 Meena 的确性能出众,不过 Meena 究竟何时能推出、真正推出后表现如何,可能都要打问号。博客中提到,目前研究团队正在就这一研究的风险及益处做进一步的评估,并可能在未来几个月内推出 Meena,旨在推动该领域的发展。
对此,VentureBeat 记者 Ronald Ashri 在其报道中表示:
首先我们要意识到,即便 Google 开源所有代码,也很少有人能培训类似 Meena 的模型。Meena 应该还在实验室里,操作起来也非常复杂,还不能将其整合到一个工具中,而且 Google 也不可能很快就将其作为一项服务向用户更好的提供。因此,恐怕短期内 Meena 难以推出。
另外,在实用性方面,诚然 Meena 作为一款开放领域聊天机器人,能够实现多轮对话。不过 Meena 并不能协助用户完成某项任务、学习某项新技能,或为身处困境的用户给予情感或心理支持,和用户的聊天没有明确的目的。而耗费时间进行无意义的交谈,在我们所处的时代大背景下似乎并非理想产品。
与此同时,记者 Ronald Ashri 也对 Meena 提出了进一步质疑。正如上文所述,Google 从公共领域社会化媒体对话上过滤得到了 341GB 的文本,以此进行进一步的训练。那么,数百万的公共领域社会化媒体对话会是这一所谓的「史上最强聊天机器人」的正确数据集吗?Meena 是否会讲出不恰当的话,可能也是一个我们要关注的点。
近年来,随着慢慢的变多的 AI 聊天解决方案进入生活,我们应该关注最有价值的东西——定义类似人类的对话,并探究这类对话在聊天机器人领域中的角色。
正如 Ronald Ashri 所说:
Meena 让我们更接近目标,但尚未让我们达到目标。
参考:
https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!













