

人类的智能涉及多个模态:我们整合视觉、语言和声音信号,从而形成对世界全面的认识。然而,目前大多数的预训练方法仅针对一到两种模态设计。
在本文中,我们提出了一种多模态自监督预训练框架「i-Code」,用户可以灵活地将视觉、语音和语言的形式组合成统一的通用的向量表征。在该框架下,我们首先将各个模态的数据输入给预训练的单模态编码器。接着,我们通过多模态融合网络集成各单模态编码器的输出,该网络使用新型注意力机制等架构创新,有效地融合了不同模态的信息。
我们使用新的目标端到端地预训练整个系统,新的目标包括掩码模态单元建模和交叉模态对比学习。不同于以往只使用视频进行预训练的研究,i-Code 框架可以在训练和推理过程中动态处理单模态、双模态和三模态数据,灵活地将不同的模态组合投影到单个表示空间中。实验结果表明,在 5 个视频理解任务和 GLUE NLP 基准测试上,i-Code 的表现相较于目前最先进的技术的提升高达 11%,展示了集成多模态预训练的威力!
真正的类人智能要考虑来自各种信号和感觉器官的信息。智能系统应该是综合的,引入来自所有可用模式的信号。在许多实际的数据体系中,我们可以利用视觉(V)、语言(L)和语音/音频(S)模态的数据。目前,研究者们在建立理解单模态、双模太的模型方面取得了巨大的进展,然而将这些工作推广到能够同时解译视觉、语言、语音的三模态系统上仍然是一项艰巨的任务。
三模态训练需要大量的三模态数据(例如,带文字描述的视频),而此类数据的规模往往比可用的单模态或双模态数据小好几个数量级。例如,目前最大的带标注的视频数据集由 1.8 亿段视频组成,而最大的图像描述数据集则包含高达 9 亿个图文对。
为了解决该问题,本文提出了两种解决方案。首先,除了三模态视频,我们还利用了大规模的双模态数据,例如:带有文本描述的图像(V+L)、带有转写文本的语音(S+L)和视频描述(V+S)。这极大地扩展了模型输入数据的规模和多样性,同时涵盖了全部三种目标模式。其次,我们提出了一种融合架构,可以采用研究社区提出的最先进的单模态编码器的上下文输出,而非从头开始构建一个独立的模型。
本文提出了「i-Code」,其中 i 代表集成多模态学习。我们开发了一个有效的融合模块,该模块集成了单模态编码器的输出,进行跨模态理解,从而获得最终的预测结果。为了设计最佳的融合架构,我们试验了多种 Transformer 架构内的自注意机制的变体,包括交叉和合并不同模态的注意力得分的机制。
接着,我们使用各种自监督目标利用双模态和三模态数据对 i-Code 进行预训练。这些目标包括:(1)掩码单元建模。其中所有输入信号都被转换为离散的词例(Token),旨在预测各模态下的被遮蔽的单元的正确词例。(2)对比学习。给定两种输入模态,模型预测给定的信号是否来自训练数据中的同一个三元组(或数据对)。
我们在多个多模态对比基准上彻底评估了 i-Code。实验结果证明了所提出的多模态预训练框架的有效性。对 i-Code 进行微调,相较目前最先进,我们可以在 6 个多模态数据集和 GLUE NLP 基准测试中的算法获得 11% 的性能提升。
视频中包含了视觉、语言、语音三种模态的数据。我们选用了最近发布的视频数据集 YT-Temporal-180M,使用给定的视频编号和时间戳收集了其中的 1.8 亿个视频片段,每个片段的平均长度为 7.8 秒。对于每个片段,我们平均采样 8 帧作为视觉输入,提取到的原始音频波形会被下游的语音编码器进一步处理。每个片段还带有一个文本脚本,改脚本是对原始 ASR 转录仔细去噪之后得到的。
然而,视频数据中存在帧和转录文本之间对齐不准的问题。为此,我们使用Azure 认知服务的 API 为每个视频片段的高分辨率中间帧生成字幕,以增强视频数据集。
由于高质量的三模态视频的规模有限,我们还使用了双模态数据集进行预训练,这已被广泛应用于视觉语言表示学习等应用、零样本跨模态生成、自动语音识别(ASR)和文本转语音(TTS)等应用。这也是成对数据的数据集首次被用于训练「视觉-语言-语音」模型。i-Code 在预训练期间使用了以下双模态数据集:
(1)视觉-语言:使用来自 Florence 计算机视觉基础模型的预训练数据中的7,280 万对「图像-描述文本」对。
(2)语言-语音:使用内部的 75 小时的英语语音转录数据。该数据集包含 6,320 万对「转录-语音」对,涉及 Cortana、远场语音和呼叫中心等多样化的场景。
(3)视觉-语音:使用了视频叙事数据集 SMiT,该数据及包含 500,000 段语音描述文本,每段文本描述了短视频中一系列不同的事件。
模型架构
i-Code 由四个模块组成。前三个模块是分别用于视觉、语言、语音的单模态编码器。最后一个模块是模态融合网络。首先,我们将每个模态的原始输入输入到对应的单模态编码器中。然后,我们通过线性投影层处理所有编码后的输入,通过模态融合网络集成它们。i-Code 可以处理各种输入:单模态输入,两种模态的任意组合,全部三种模态一起输入。
我们并非从头开始训练每个单模态编码器,而是设计了一个模块化的框架:可以使用任何预训练的模型替换单模态编码器。这为融合网络提供了高质量的上下文表征,从而进行更有效的多模态理解。我们采用了各种模态的最先进的编码器:
(1)语言编码器:采用 DeBERTa V3 base,该预训练模型包含 1.83 亿参数,用到了解耦注意力机制。
(2)视觉编码器:采用 CoSwin Transformer。为了使 i-Code 可以处理图像和视频帧序列,我们利用预训练的 CoSwin Transformer 实例化了一个视频 CoSwin Transformer,该模型包含 9,100 万参数。
(3)语音编码器:采用预训练的 WavLM-large 模型,该模型包含 3.15 亿参数,使用了时域卷积编码器提取输入语音波形,并进一步使用 transformer 编码。值得注意的是,我们还可以使用其它的单模态编码器来组成 i-Code 架构。
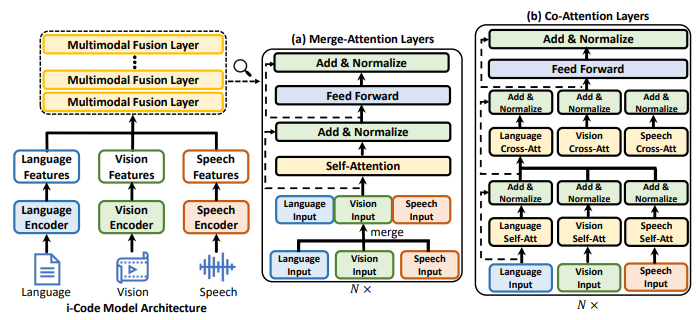
图 1:(左)i-Code 模型架构(右)融合网络中的注意力和前馈网络操作。
模态融合模块
每个单模态编码器提取的特征会通过单层前馈网络投影,其维度等于融合网络的隐藏维度。我们将投影的特征输入给模态融合网络,生成集成的多模态表征。由于单模态编码器已经包含了位置信息,我们在融合模块中不使用位置嵌入。融合网络的主干是一个 Transformer 编码器,其中每一层都会执行跨模态注意力、前馈投影和层归一化。如图 1 所示,为了促进更有效的跨模态理解,我们探索了传统注意力机制的两种变体:融合注意力和协同注意力。
融合注意力
此时,不同的模态共享相同的注意力参数。为了帮助融合模块区分不同的模态,我们在所有时间和空间维度上,将每个模态独有的识别嵌入添加到投影后的特征上(在所有的时间和空间维度上)。我们将来自不同模态的投影特征连接在一起,输入给融合网络,融合网络的每一层都与经典的 Transformer 编码器层相同。
协同注意力
此时,每个 Transformer 层首先在每个模态内部的特征之间执行自注意力机制,每个模态都具有模态特定的注意力参数。假设前一个 Transformer 层的语言、视觉和语音输出分别为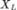 、
、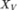 和
和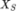 。以语言模态的单个注意力头为例:
。以语言模态的单个注意力头为例:
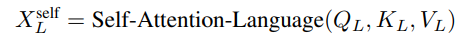
我们在自注意力子层后应用一个跨模态注意力:
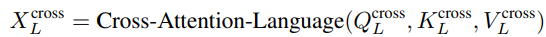
对于具有融合注意力机制的融合网络模块,我们使用了 6 个 Transformer 编码器层,隐层的向量维度为 768,融合模块有 1.54 亿个参数。对于协同注意融合模块,为了保持模型的维度与融合注意力模型相近,我们使用了 3 层 Transformer,隐藏维度相同,最终的模型具有 1.63 亿个参数。融合模块中的参数在预训练中随机初始化,而不是从预训练的 Checkpoint 上被实例化。
掩码单元建模
此类自监督预训练目标包括:
(1)掩码语言模型(MLM)。MLM 在针对语言和「视觉-语言」预训练的自监督学习方面取得了显著的成功。在预训练过程中,我们将 30% 的文本词例屏蔽掉。模型需要预测被屏蔽掉的词例,损失函数为真实值和预测词例索引之间的交叉熵。
(2)掩码视觉模型(MVM)。我们在视觉自监督学习中采用了与 MLM 一致的高级策略。我们将视觉输入转换为离散词例,屏蔽输入图像中的某些区域,并最大化被屏蔽区域的预测值和真实词例之间的交叉熵。给定一组帧序列,我们利用目前最先进的视觉矢量量化变分自编码器(VQ-VAE)——PeCo,将每一帧离散为词例。我们采用 Wang 等人在论文「Bevt: Bert pretraining of video transformers」中提出的 3D tube 掩码策略,跨时间维度屏蔽图像区域进行掩蔽,每一帧屏蔽 50% 的区域。
(3)掩码语音片段模型(MSM)。使用预训练的 wav2vec 2.0 语音量化器模型将语音离散化为词例序列。我们使用与 HuBERT 和 wav2vec 2.0 相同的掩码策略,随机选择 p% 的时间步作为起始的索引,并屏蔽接下来的 L 步语音片段。此时,我们取 L=10、p=8。MSM 损失 为预测标签和真实标签之间的交叉熵。
为预测标签和真实标签之间的交叉熵。
跨模态对比学习
我们先将每个单模态输入通过相应的编码器编码,然后将编码结果分别送入多模态编码器。接下来,对每组单模态嵌入进行平均池化。对于语言和语音模态,多模态编码器输出沿时序维度取平均。视觉输入则同时沿时间和空间维度取平均。我们分别将视觉、语言和语音的所获得的表征表示为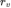 、
、 、
、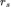 ,并且将表征归一化为单位向量,例如:
,并且将表征归一化为单位向量,例如: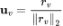
每个 batch(B)中的视觉语言对比损失 为:
为:
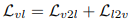
其中,「视觉到语言」、「语言到视觉」的对比学习目标函数为:
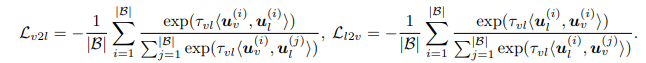
类似地,我们分别定义了「视觉-语音」、「语言-语音」的对比学习目标函数和。
在对视频进行预训练时,我们将视频描述和 ASR 转录文本连接起来作为视觉语言对比学习和 MLM 的语言输入。预训练目标函数是掩码单元建模和对比学习目标的加权和:
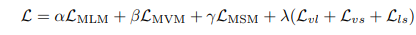
我们在多模态情绪&情感分析、多模态推理、视频问答以及一些单模态任务上评估了 i-Code 模型的性能。
多模态情绪&情感分析
我们在迄今为止最大的多模态情感分析和情感识别数据集 CMU-MOSEI 上测试了 i-Code,该数据集包含 23,453 段视频,提出了两个任务:情绪分析和情感识别。
就情绪分析任务而言,给定一段视频,模型需要预测说话人的情绪水平,其范围为高度消极(-3)到高度积极(3)。评价指标为 MAE、预测情绪标签和真实情绪标签之间的相关性(Corr)和 F1 得分。该数据集还可以被用于构建二元分类任务评估模型,将-3到-1分作为一个类别,将1到3分组作为另一个类别。
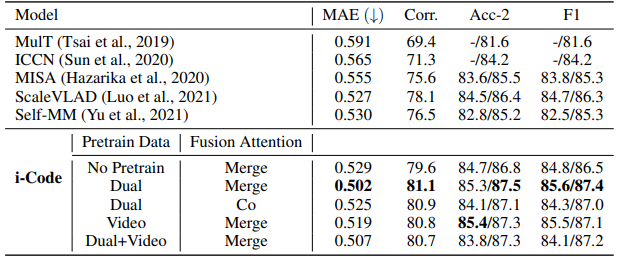
表 1:CMU MOSEI 情绪分析结果
我们测试了 i-Code 使用不同融合注意力机制、预训练数据时的性能。如表 1 所示,i-Code 在 CMU MOSEI 情绪分析任务上取得了目前最佳的性能。在 Dual 数据集上训练的 i-Code 模型比在视频数据集上训练的 i-Code 模型展现出了更好的性能。在此数据集上,融合注意力的性能优于协同注意力机制。即使不进行多模态预训练,利用最先进的编码器的 i-Code 已经展现出与以前的模型相比具有竞争力的性能。
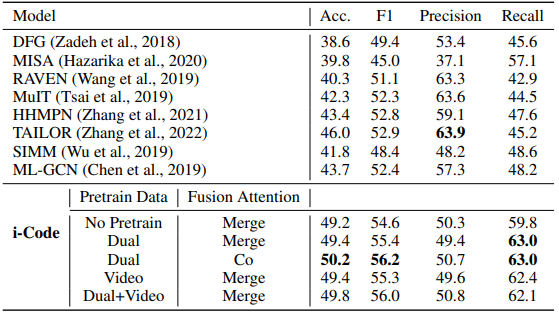
表 2:CMU MOSEI 情感识别结果
就情感识别而言,我们按照 Ekman 情感分析体系为视频赋予以下标签:快乐、悲伤、愤怒、恐惧、厌恶、惊讶。评价指标为准确率(accuracy)、精度(precision)、召回率(recal)和 Micro-F1。我们在未进行模态对齐的数据集上评估模型性能。如表 2 所示,相较于之前的最佳模型,i-Code 的准确率提高了 4.1%,F1 提高了 3.3%,协同注意力的性能优于融合注意力。同时利用 Dual 数据和视频数据进行预训练,可以有效提升模型性能。

表 3:UN-FUNNY 二分类结果
我们在 UR-FUNNY 数据集上测试了 i-Code 在情感二分类任务上的性能。给定一段视频帧和声音,模型需要预测该片段是否会立即引起笑声。对比基线包括Bi-Bimodal 融合网络、低秩矩阵融合、MultiBench、张量融合网络等利用了三模态输入的模型。如表 3 所示,i-Code 模型的准确率相较于之前最优的模型高出了 7.5%,使用视频预训练和融合注意力融合网络时的性能最优。
多模态推理
我们使用 VIOLIN 数据集评估 i-Code 的跨模态推理能力,该数据集的输入是一段剪辑自电视节目的视频片段。该片段由视频帧 V、对齐后的描述文本 T 和音频 S 组成。模型的任务是判断文本假设 H 与视频片段矛盾还是相符。我们将融合网络输出的平均值作为多模态表征,并以此训练一个二分类器。如表 4 所示,i-Code 的准确率相较于之前最优的对比基线提升了 3.5%。其中,D、V、NP 分别代表使用 Dual、视频作为预训练数据和不使用预训练数据;M、C 分别代表使用融合注意力机制和协同注意力机制。

表 4:VIOLIN 数据集上的多模态推理结果
视频问答
在视频问答(VQA)任务中,给定一段包含视频帧 v、视频描述 t、音频 s 的视频,以及问题 q。问答系统需要从若干候选答案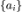 中选择出正确的答案。我们将问题、候选答案、文本描述连接起来作为文本输入。接着,我们将文本输入、视频帧、语音波形一起输入给 i-Code 模型,对各模态的输出取平均,得到
中选择出正确的答案。我们将问题、候选答案、文本描述连接起来作为文本输入。接着,我们将文本输入、视频帧、语音波形一起输入给 i-Code 模型,对各模态的输出取平均,得到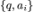 的多模态表征
的多模态表征 。我们通过投影层将表征转换为 logit 得分,并将 softmax 应用于这些得分得到分类概率。
。我们通过投影层将表征转换为 logit 得分,并将 softmax 应用于这些得分得到分类概率。
我们分别在 How2QA、KnowIT 数据集上测试了 i-Code 在视频问答任务上的性能。How2QA 包含来自 HowTo100M 的 37,000 daunt视频片段;KnowIT 包含 24,282 个人类标注的问答对,每个问题附有 4 个候选答案。实验结果如表 5 和表 6 所示。

表 5:How2QA 数据集上的视频问答性能

表 6:KnowIT 数据集上的视频问答性能
单模态任务
我们进一步研究了 i-Code 单模态任务上的表现。纯语言NLP任务)上的表现。如表 7 所示,我们将 i-Code(D+M)与之前发布的多模态模型以及参数量相当的语言模型进行了比较。
实验结果表明,i-Code 大幅提升了多模态模型的性能,相较于之前最先进的模型,其平均得分提高了 11%。与之前的纯语言模型相比,i-Code 也表现出了更强的性能,在 7 个任务以及整体性能上都超过了 DeBERTa V3 。
以往,多模态模型(尤其是视觉语言模型)中的语言编码器的性能通常在只涉及语言的任务上相较于语言模型较弱。这种性能差距通常是由于多模态数据集中的语言数据质量较差导致的。我们推测,掩码语言建模目标以及语言-语音对比学习有助于 i-Code 缩小这一差距。
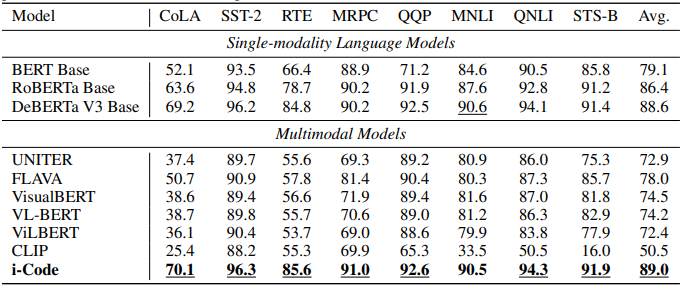
表 7:在语言任务(GLUE)上与之前的模型的性能对比。
如表 8 所示,以 MOSEI 情感识别任务为例,我们发现仅使用单一模态数据时,语音是最有效的。这也许是因为音色能够反映出人类的情感。使用双模态数据比使用单模态数据的性能往往更好。在使用双模态数据时,使用「语言-语音」可以获得最佳的模型性能。
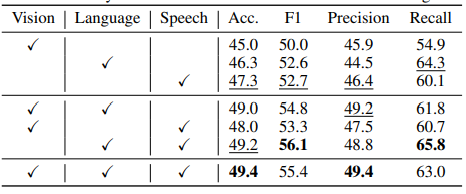
表 8:CMU MOSEI 情感识别任务上的模态消融实验结果
此外,在大规模多模态数据集上的自监督预训练显著提升了模型性能。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!













