6月14日,腾讯Robotics X机器人实验室公布了智能体研究的最新进展,通过将前沿的预训练AI模型和强化学习技术应用到机器人控制领域,让机器狗 Max 的灵活性和自主决策能力得到大幅提升。
让机器狗像人和动物一样灵活且稳定的运动,是机器人研究领域长期追求的目标,深度学习技术的不断进步,使得让机器通过“学习”来掌握相关能力,学会应对复杂多变的环境变得可行。
引入预训练和强化学习:让机器狗更加灵动
腾讯Robotics X机器人实验室通过引入预训练模型和强化学习技术,可以让机器狗分阶段进行学习,有效的将不同阶段的技能、知识积累并存储下来,让机器人在解决新的复杂任务时,不必重新学习,而是可以复用已经学会的姿态、环境感知、策略规划多个层面的知识,进行“举一反三”,灵活应对复杂环境。


这一系列的学习分为三个阶段:
第一阶段通过游戏技术中常使用动作捕捉系统,研究员收集真狗的运动姿态数据,包括走、跑、跳、站立等动作,并利用这些数据,在仿真器中构建了一个模仿学习任务,再将这些数据中的信息抽象并压缩到深度神经网络模型中。这些模型能够非常准确地涵盖收集的动物运动姿态信息,且具有一定的可解释性。
腾讯Robotics X机器人实验室和腾讯游戏合作,用游戏技术提升了仿真引擎的准确和高效,同时游戏制作和研发过程中积累了多元的动捕素材。这些技术以及数据对基于物理仿真的智能体训练以及真实世界机器人策略部署起到了一定的辅助作用。
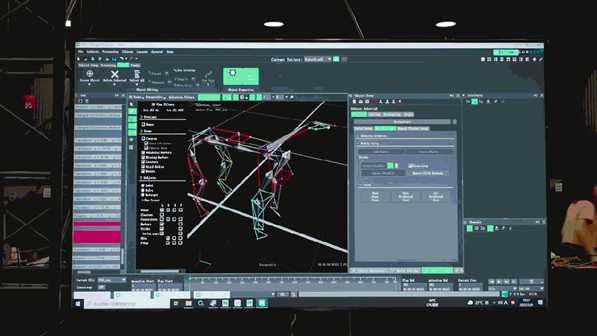


在模仿学习的过程中,神经网络模型仅接收机器狗本体感知信息作为输入,例如机器狗身上电机状态等。再下一步,模型引入周边环境的感知数据,例如可以通过其他传感器“看到“脚下的障碍物。
第二阶段,通过额外的网络参数来将第一阶段掌握的机器狗灵动姿态与外界感知联系在一起,使得机器狗能够通过已经学会的灵动姿态来应对外界环境。当机器狗适应了多种复杂的环境后,这些将灵动姿态与外界感知联系在一起的知识也会被固化下来,存在神经网络结构中。




第三阶段,利用上述两个预训练阶段获取的神经网络,机器狗才有前提和机会来聚焦解决最上层的策略学习问题,最终具备端到端解决复杂的任务的能力。第三阶段附加的网络会获取与复杂任务有关的信息,例如在游戏中,获取对手的信息、旗子的信息。此外,通过综合分析所有信息,负责策略学习的神经网络会学习出针对任务的高阶策略,例如往哪个方向跑动,预判对手的行为来决定是否继续追逐等等。
上述每一阶段学习到的知识都可以扩充和调整,不需要重新学习,因此可以不断积累,持续学习。
机器狗障碍追逐比赛 :拥有自主决策和控制能力
为了测试Max所掌握的这些新技能,研究员受到障碍追逐比赛“World Chase Tag“的启发,设计了一个双狗障碍追逐的游戏。World Chase Tag是一个竞技性障碍追逐赛组织,2014年创立于英国,由民间儿童追逐游戏标准化而来。一般来说,障碍追逐比赛每轮次由两名互为对手的运动员参加,一名是追击者(称为攻方),一名是躲避者(称为守方),当一名运动员在整个追逐回合中(即20秒)成功躲避对手(即未发生触碰)时,团队将获得一分。 在预定的追逐回合数中得分最多的战队赢得比赛。
在机器狗障碍追逐比赛中,游戏场地大小为4.5米 x 4.5米,其中散落着一些障碍物。游戏起始,两个MAX机器狗会被放置在场地中的随机位置,且随机一个机器狗被赋予追击者的角色,另一个为躲避者,同时,场地中会在随机位置摆放一个旗子。
追击者的任务是抓住躲避者,躲避者的目的则是在保证不被抓到的前提下去接近旗子。如果躲避者在被抓到之前成功触碰到旗子,则两个机器狗的角色会瞬间发生互换,同时旗子会重新出现在另一个随机的位置。游戏最终的结束条件为当前的追击者抓住了躲避者,且当前为追击者角色的机器狗获胜。所有游戏过程中,两个机器狗的平均前向速度被约束在0.5m/s。

从这个游戏看来,在基于预训练好的模型下,机器狗通过深度强化学习,已经具备一定的推理和决策能力:
比如,当追击者意识到自己在躲避者碰到旗子之前已经无法追上它的时候,追击者就会放弃追击,而是在远离躲避者的位置徘徊,目的是为了等待下一个重置的旗子出现。

另外,当追击者即将抓到躲避者的最后时刻,它喜欢跳起来向着躲避者做出一个”扑”的动作,非常类似动物捕捉猎物时候的行为,或者躲避者在快要接触旗子的时候也会表现出同样的行为。这些都是机器狗为了确保自己的胜利采取的主动加速措施。
据介绍,游戏中机器狗的所有控制策略都是神经网络策略,在仿真中进行学习并通过zero-shot transfer(零调整迁移),让神经网络模拟人类的推理方式,来识别从未见过的新事物,并把这些知识部署到真实机器狗上。例如下图所示,机器狗在预训练模型中学会的躲避障碍物的知识,被用在游戏中,即使带有障碍物的场景并未在Chase Tag Game的虚拟世界进行训练(虚拟世界中仅训练了平地下的游戏场景),机器狗也能顺利完成任务。

腾讯Robotics X机器人实验室长期致力于机器人前沿技术的研究,以此前在机器人本体、运动、控制领域等领先技术和积累为基础,研究员们也在尝试将前沿的预训练模型和深度强化学习技术引入到机器人领域,提升机器人的控制能力,让其更具灵活性,这也为机器人走入现实生活,服务人类打下了坚实的基础。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!