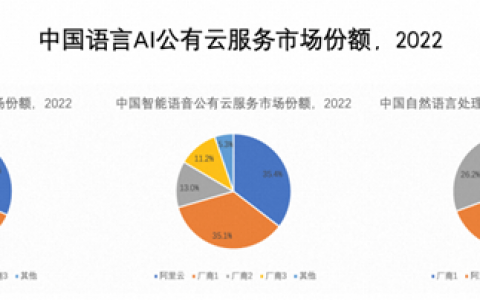
2015年从微软离职的简仁贤,创办了竹间智能,从成立之初,竹间智能就专注于AI技术的研发,并在NLP(自然语言处理)领域下足了功夫。
但值得注意的是,彼时国内对NLP的研发还处于空白,也没有一款成熟的NLP产品出现。竹间智能作为一家初创企业为何选择去填补这块空白?
其实从简仁贤以往的履历中就能得到答案“2006年加入微软负责Bing核心产品的研发、2012年担任微软亚洲互联网工程院副院长,负责微软亚太地区的搜索及AI产品的技术研发,并主导开发微软小娜(Cortana)……”
可以说,这些宝贵的经验是竹间智能研究NLP的弹药,但这并不意味着其NLP的研发之路是一帆风顺的。创办初期,简仁贤带领团队专心搞研发,2017年开始尝试做商业化探索,2020年形成规模化发展。目前竹间智能已经为600多家客户做了NLP的落地。
转眼到2023年,在人们还在谈论大模型怎么做的时候,竹间智能就推出了大模型工厂(LLM Factory)。很多人认为,这是其长期深耕NLP技术,厚积薄发的结果,简仁贤也并不否认这一点。
同时,小编还了解到,早在2021年GPT 2刚出来时竹间智能就开始研究,并逐渐把机器学习平台往大模型上迁移。因为在简仁贤看来,等大模型火了之后再做就来不及了,很多东西等所有人看明白后再去做就是红海了。
反观国内大模型的发展,确实如此。从大模型的概念火出圈后,国内出现了多家大模型产品,诸如百度的文心一言、阿里商务千义通问、讯飞星火认知、商汤日日新…比比皆是,有关大模型的讨论也都是“参数是多少、做到什么程度了等等。”
简仁贤坦言,现在人们更愿意每天在媒体上面看谷歌怎么样了,Meta怎么样了,OpenAI怎么样了,谁谁谁怎么样了,这些都是趋势,不能反映企业内部的问题,这时大模型厂商真正要做的是,在企业预算资源有限的情况下,帮助企业把大模型融入到业务系统中,做增强,做赋能。
“竹间智能不会开发布会哗众取宠,也不会向别人吹嘘自己的技术有多牛,而是让每个人都用到这项新技术,创造出能给用户带来价值的大模型产品。”
对此,简仁贤还特别举例道:“如果你和家里人说我有个大模型,他们可能无法理解你在说什么,但如果你说有个APP,你只需跟它说几句话,它就能帮你写信,他们反而能迅速理解并接受,他们才不会关心你背后是大模型还是什么。”
以下是小编和简仁贤的对话:
像特斯拉Model一样,做量化,让大模型更平民化
小编:从什么时候开始关注大模型的?
简仁贤:实际上我们已经在大模型的研究领域耕耘超过两年的时间。自2021年GPT2问世,我们就开始关注了,并将机器学习平台向大模型开发方向迁移。
小编:大模型工厂(LLM Factory)是大模型火了之后开始做的吗?
简仁贤:不是,从2021年起,尽管大模型当时并未大热,竹间就开始关注大模型了,2022年中开始研究,现在我们已在内部进行应用实践。
小编:为什么开始的这么早?
简仁贤:大模型火了之后,后期投入的企业面临逐渐饱和的市场,也就是红海。越早开始,积累的经验就越丰富,而后期投入则不可避免地要面对各种问题,这些问题我们往往已经解决过,现在的道路已经相对平坦。我们在自然语言处理(NLP)领域的深耕已有近8年,大语言模型也是NLP领域,最大的突破是生成式AI以及将大语言模型训练工程实现,现在企业面对的挑战是如何克服大模型的落地的种种挑战,将大语言模型应用到业务场景中,达到业务的效果,而不是只有炫技。近8年来,企业对我们的信任度高,我们也深入理解他们在NLP的需求,有助于企业将大语言模型落地。
小编:大模型工厂(LLM Factory)具体可以做什么?
简仁贤:大语言模型工厂(LLM Factory)的运行机制非常复杂,整条模型训练微调的流水线从数据梳理清洗,人工标注,到选择预训练基础模型,实验不同的微调方法,不同人物进行多次微调,并评估模型结果,再加入人工反馈强化学习机制,上下文学习,等等,进而自动化地完成模型交付。如今,我们已经拓展了原有积累多年的自动化机器学习平台和数据标注运营平台,因此在这个系统上,我们可以训练微调出许多不同的大模型,依照企业的需求,实现专属于企业的定制化行业大模型的落地。
各种模型都可以有不同大小的 size, 不同数量级的参数,这就好比我们喜欢的衣服有S、M、L、XL、XXL各种尺码,我们可以从以前的S尺码模型做到现在的M、L,甚至是XL尺码的模型。而且,我们所做的是能批量生产的模型,就像特斯拉的Model系列一样,我们并非只做一款模型,而是要能生产出N款模型。
小编:竹间做这件事情,对企业最大的好处是什么?
简仁贤:对于绝大多数的企业客户来说,他们无法投入数千万资金进行从0开始的基础大模型的预训练,即使有资金也无法做得到,数据,算力,know-how,维护等。那竹间提供的大模型工厂(LLM Factory)可以在短时间内,快速且低成本的,帮助企业构建自己的大模型,将其部署到本地并与现有系统融合,从而协助企业进行业务的升级。客户将可以直接看到效果,竹间提供从准备数据,模型微调,最有效的微调方法,将微调训练的know-how开发到EmotiBrain的模型工厂中,而且成本相对较低,无需自备GPU资源,既可以享有定制化的大模型。
小编:所以让客户低成本的享受大模型的能力,也是我们重点要做的?
简仁贤:我们的目标就是将人工智能平民化,让所有的企业都有自己的大模型,都能负担得起的大模型,甚至我们设定一个目标:成立99万大模型试验室,让企业在99万的预算内即可打造一个企业自有的大模型,让大模型变得更为平民化。此外,我认为企业所需的并非仅仅是一个大模型,而是多个大模型,使用 EmotiBrain Model Factory,能高效训练微调大模型,更能进一步降低成本。
小编:和以前相比,客户的态度有转变吗?
简仁贤:我们之前也推广过大模型,花费了大量时间去教育市场和客户,但是由于门槛比较高,客户也需要购买GPU,当时很多客户并没有充足的预算,也无法理解大模型能带来的实际效果,所以推广效果并不明显。
随着今年大模型的爆发,现在大多数客户都明白了大模型能够给企业带来什么样的价值。目前,我们正在与数十个客户进行商谈,他们对大模型还是比较接受的。
大模型自研与否不重要,关键要走最后一公里路
小编:您怎么定义竹间在大模型方面的服务模式?
简仁贤:我们提供Model-as-a-Service,模型即服务,这意味着我们的产品和工具平台可以快速帮助客户构建模型,而且这个模型可以迅速地与企业的业务系统进行连接。这就避免了客户需要购买大量的GPU,或是纠结于如何选择合适的模型,或者是走进大笔经费的无效投入。我们会根据客户的需求帮他们定制适合的模型,无论是70亿参数,130亿参数,还是650亿参数的大模型,都在我们大模型工厂(LLM Factory)的服务范围内。
小编:具体怎么帮企业选择合适的模型?
简仁贤:EmotiBrain 有大模型商店,里面有预训练好的行业大模型,不同任务的专有模型,我们还拥有一套实际的Benchmark系统,可同时训练,评估,及比较多个大模型。比如,设定三种模型,三种不同的微调训练方法,以及三种不同的训练数据,就可以训练出27种不同的模型。完成训练后,我们的Benchmark 系统可以对训练结果进行比较,然后根据客户的不同业务场景与目标,为他们选择最合适的模型,企业不再需要花大钱组建模型训练团队。
小编:竹间的大模型是自研的还是?
简仁贤:我们的大模型开发有两种方式:一是自主研发,二是基于其他预训练的大模型进行开发。
种方式我们都采用,快速在企业场景中,落地应用,快速验证可商用化。如果坚持所有事情都从零开始,在企业落地阶段,可能并不现实。
小编:所以您认为,大模型是不是自研已经不重要了?
简仁贤:坦率来说,目前绝大多数的生成式AI都是基于谷歌开发的 Transformer 开发出来的模型, 如果谷歌没有开源Transformer,OpenAI就没法开发出ChatGPT,也就不会有GPT 4;之后谷歌的PaLM 2也用了 GPT-4 来生成训练数据。此外,最流行的开源大模型是基于Meta开源的LLaMA模型(参数权重需要商用许可),大多数2023年发布的大模型也都是机遇开源的基础模型框架来训练的,或者是基于不同模型用不同数据与不同训练方法开发出来的,未来的软件世界,实用的,可商用化的,都不会是原始的基础模型。
小编:那什么才是最重要的?
简仁贤:真正重要的是,最后用大模型驱动做出的产品是否有实际应用价值。就像我刚才举的例子,Transformer是谷歌开源的,但是在谷歌的PaLM 2中使用的训练数据是从GPT 4产生的语料中获取的。那么GPT 4的训练语料是谁做的呢?并不一定是GPT 4,可能是收集其他软件的人类使用数据,如 Twitter, Reddit, 等。因此,未来软件的新范式应该是:谁能够做出让用户享受到成果的产品,谁能够把最后一公里打通,就是最有价值的,当然要能保障数据安全,模型安全,并与人类对齐。
小编:这样一来,微软谷歌做的事情岂不是都没有价值了?
简仁贤:实际上,OpenAI并不仅仅是做底层的工作,他们也在进行应用开发。微软也同样如此,他们使用GPT 4为Office全家桶和Bing等产品做了升级,他们所做的就是“最后一公里”的工作。谷歌也是一样,与OpenAI一样开发AGI,并且在为自己的产品以大模型的能力升级,谷歌和微软的大模型都还是闭源的。
大模型+知识+应用,才是未来软件的范式
小编:业界有人说以前的软件范式是信息+连接,未来是知识+陪伴,您认为未来软件的新范式是什么样的?
简仁贤:我认为未来软件的范式是“大模型+知识+应用。”
小编:多了一个“应用,”这个逻辑是怎么推论出来的?
简仁贤:我始终坚信,能够触及用户的产品才是最具价值的。比如,在我们今天谈论科技时,全球近80亿的人口中,大部分人对大模型这些高科技概念并不了解,他们碰不到、摸不到、看不到。目前要把大模型用好,需要很好的提示词,这个99%以上的人是不会的,绝大多数的人他们只关心自己所使用的产品的性能能不能给他们带来价值,所以应用最重要。
我在之前几次演讲中也提到过,模型与用户之间存在着一道巨大的鸿沟。那么,如何架设一座桥梁跨越这个鸿沟呢?这座桥就是应用,就是产品。因此,我认为未来的软件范式是“模型+知识+应用”。如果只有模型和知识,却没有应用,那么它就无法被人们所接受。
模型是否有价值?我举个例子,如果你回家跟家里的老人和孩子说:我有一个大模型,他们可能无法理解你在说什么。但如果你说:我有一个应用程序,你只需对它说几句话,它就能帮你写信。这样他们就能迅速理解并接受,他们不会关心这个应用程序背后是否有大模型。
因此,企业的目标应该是让每个人都能使用到技术,而不是向外界夸耀自己的技术有多么强大。我们的愿景是让每个人都能拥有一个机器人。
小编:机器人的概念怎么理解?
简仁贤:机器人的中枢就是大模型,但这个机器人是一个应用,它可以帮助人们完成任务。这就是我们的价值观——只有模型是没有用的,正如OpenAI一样,尽管它的很多论文很难懂,但是它创造出了ChatGPT这个应用,给大模型一个与人类沟通的一个界面,将大模型到应用的全过程实现了,让全世界都能在一个界面上利用大模型完成各种任务,因此它才能如此成功。
小编:那竹间应用层的产品接入大模型的能力了吗?
简仁贤:我们原有的4个产品都已经具备大模型的能力,并且已开发的四种应用也是基于大模型的原生产品,我们的SaaS 产品也已经接入大模型了,也已经开放给许多客户试用了。
做好数据梳理,帮企业落地模型才是王道
小编:与通用大模型相比,竹间做大模型的意义是什么?
简仁贤:通用人工智能,AGI,并不能真正解决企业的业务问题,绝大多数的公司都不能把自己的私有数据上传出去。因此,每一家企业都会想要建立自己的大模型,这为我们带来了万亿级别的商机,即如何帮助企业快速建立大模型。发布会所看到的大模型并不一定具备可商用化的质量,我们重视的是如何将模型打造成可商用化的大模型,务实地帮助企业实现大模型的落地。
小编:具体怎么帮企业做落地?
简仁贤:我们提供的服务相当于预先训练好基础模型,将该模型部署到我们的大模型工厂(LLM Factory))上,再将其部署到客户端,允许客户使用自己的数据来训练自己的模型,并自动集成到企业的应用中。
小编:这是我们和其他厂商相比,最具优势的地方吗?
简仁贤:对。像Open AI的GPT-4,由于模型参数庞大,需要的训练数据与维护工作量庞大,寻要的GPU资源更高达24000张A100-80G的GPU,是不可能将GPT-4这样的模型部署到客户端去操作。更实际的,企业并不需要上千参数量的大模型,大部分的需求,用7B或13B都能完成。我们的通用大模型和模型工厂部署到客户端,结合客户的数据和行业know-how,再进行参数调整,便能微调训练出一个7B-65B的大模型。这个模型留在客户端,属于客户所有,而不是我们。我们更提供了终端的应用,让企业能快速享受到大模型带来的业务价值。
小编:其实这也在一定程度上解决了数据安全的问题?
简仁贤:我们的大模型服务强调的是数据安全和模型安全,事实上,模型安全更为重要,因为企业的许多know-how都融入了模型中。如果一个企业创建了一个模型,然后将这个模型交给了他人,可能整个企业的机密就无法保障了。大模型是根据训练的数据来生成结果的。因此,模型安全至关重要,我们的模型工厂首先能保证数据安全,其次能保证模型安全,确保企业的所有数据都万无一失。
小编:安全问题保证了,对于竹间来说做大模型最难的是什么?
简仁贤:数据梳理。数据梳理和数据标注是两个概念。
其实对于我们来说,创建大模型不难的,因为我们有know-how,真正的难点在于客户需要整理数据。举例来说,如果要整理过去10年小编的所有文章,筛选出所有与人工智能相关的文章,你们公司有谁可以完成这项任务?需要多长时间?这是一项复杂的任务,需要大量的人力。
小编:所以说,这也是对客户的挑战?
简仁贤:对。在国内,高质量,梳理过的数据短缺是一大问题,特别是有效的中文数据更是稀缺,缺少能使用到模型训练微调的高质量的数据。创建企业定制化的大模型主要取决于企业自身是否有数据积累。如果没有,就很难进行,需要从数据收集和准备训练数据做起。只能使用通用大模型来解决通用问题,例如撰写文章、修改文章等简单任务。当然,很多国内外的大企业或上市公司都拥有自己的数据,但缺乏的是数据梳理方法——如何沉淀优质数据,然后去训练模型?这是最大的挑战。
小编:怎么帮客户解决这个问题?
简仁贤:在数据梳理的过程中,不存在所谓的“弯道超车”,必须积累行业经验和know-how。作为B端的服务提供者,我们在金融、能源、制造、消费、传媒等领域已经积累了丰富的经验。我们具有能为企业整理数据的know-how和工具,如果只提供大模型而不协助整理数据,不能微调大模型,那么客户将无法有效使用大模型。
不做C端,瞄准B端,坚持做企业级大模型产品
小编:和前几个月相比,您对大模型的发展有改观吗?
简仁贤:近期大模型的发展和我几个月前的预测存在一些出入。谷歌并未开源其模型,目前仍保持闭源状态。Meta目前是开源领域中最大的企业,也是大模型的主要贡献者。与谷歌和微软保持闭源策略不同,Meta的LLaMA是开源的(参数权重除外),其在整个开源世界的影响力远超谷歌和。
目前,大模型呈现两大发展趋势:一是保持闭源并走向超大型模型;另一是坚持开源并走向中大型模型。有些创业公司或大厂在做的大模型都同质性太高,没有差异化,其结果大同小异。但我认为,未来有价值的工作会是在训练微调的技术上精进,并将微调工作规模化,为企业大模型落地走完最后一公里路,而不是处在于做同质性的大模型。
小编:闭源大模型和开源大模型争夺市场有什么不同?
简仁贤:闭源大模型争夺的是C端市场,而开源大模型争夺的是B端市场。
小编:为什么谷歌、微软不开源?
简仁贤:简单来说,他们需要通过这些模型来提高他们主营业务的获利,以提高他们的竞争力,对业务有价值的核心技术,谁会开源?
小编:听下来发现,竹间更倾向于做B端,那会不会像谷歌微软一样做超级巨大模型?
简仁贤:我们的目标并非是直接为三、四亿用户服务的超大模型,这是大企业的工作。我们的目标是为数万家有大模型需求的企业提供大模型支持与解决方案落地。另一个现实是:目前没有任何非AI企业有足够的计算资源和预算来开发通用大模型。1万个GPU的费用超过2亿美元,我们的客户,绝大多数现阶段都无法投入这么大的资金去开发超大模型,尤其是当这么大的模型并不是直接解决业务问题的。
我们在与客户交流的过程中发现,他们的需求不是高考,获取律师资格、取得MBA,他们需要的是解决自己的业务问题,而中大型模型就足以满足这一需求。
小编:您认为大模型厂商应该把重点放在哪些方面?
简仁贤:我们应该思考的是如何使企业在有限的预算下能够负担起新的AI技术,帮助他们实现内部增强。这才是大模型发展的重点,科技的进展日新月异,如何把握住最新技术,了解客户的需求,将合适的技术与产品落地到企业业务中才是我们最关注的重点。企业无法直接引入像ChatGPT这样的模型。实际上,由于不可控的因素,数据安全的隐忧,许多国家和企业已经开始限制使用ChatGPT。在这种情况下,企业如果想要享受大模型的能力,对我们来说就意味着巨大的商业机会。
在有限的预算内,帮助企业将大模型融入业务系统,才是真正值得我们关心的大模型发展趋势。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!